Can i please get a opinion on the best way to retard the spell checker.
I think making up a new language for reducing the number of words may be too much.
On the other hand, if i simply replace one of the dict files, I loose the POS tag information, which means other rules will not work?
What is the exact process to create a new language? Is my understanding of the steps involved correct?
Create a input file <voa_input.txt> with the 1500 words.
Create a .dict file using: java -cp languagetool.jar org.languagetool.dev.SpellDictionaryBuilder de-DE /path/to/dictionary.txt org/languagetool/resource/en/hunspell/en_US.info - -o /tmp/output.dict
a. What should i call this for the de-DE? I can see xx-XX is possible?
b. Where does the POS data go in for the 1500 words when I am creating the .dict file?
Alternately, do I just manually build a binary POS dictionary? That is, manually populate a text file (~1500 words only) with inflected, base and POS; and then run the POSDictionaryBuilder?
Finally - what is the binary synthesizer dictionary and how is it used?
Hi, I’m not sure whether a new spell checker dictionary is the right approach here. Any correct word that’s not in the list of 1500 words would be flagged as a spelling error, which doesn’t seem quite right. Instead, I’d suggest adding a Java rule that loads the valid words from a plain text file and complains about every word not in that list. This way you can also offer useful alternatives more easily, while a spell checker can only offer alternatives based on spelling.
Adding a language is documented at Adding A New Language - LanguageTool Wiki, but this might be overkill. If you add the new Java rule as described above and make it the only active rules that’s much easier.
I have no experience in Java, and limited coding experience generally. Still, am very keen to learn. I will have a look at the DemoRule.java and try to understand how to do this. Thanks so much.
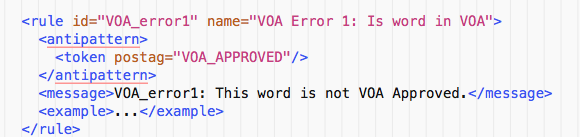
There are several ways to have exceptions, you can search for negate= or <exception> in Development Overview - LanguageTool Wiki. But what exactly happened when you used <antipattern>?
Just realized you are in the core team. Appreciate you looking at this.
grammer.xml
The error i get is:
Tathagats-iMac:LanguageTool-3.2 tathagatbanerjee$ java -jar languagetool.jar
java.lang.RuntimeException: java.lang.RuntimeException: Could not activate rules
at org.languagetool.gui.LanguageToolSupport.reloadLanguageTool(LanguageToolSupport.java:310)
at org.languagetool.gui.LanguageToolSupport.init(LanguageToolSupport.java:333)
at org.languagetool.gui.LanguageToolSupport.<init>(LanguageToolSupport.java:146)
at org.languagetool.gui.Main.createGUI(Main.java:322)
at org.languagetool.gui.Main.access$1800(Main.java:53)
at org.languagetool.gui.Main$7.run(Main.java:859)
at java.awt.event.InvocationEvent.dispatch(InvocationEvent.java:311)
at java.awt.EventQueue.dispatchEventImpl(EventQueue.java:756)
at java.awt.EventQueue.access$500(EventQueue.java:97)
at java.awt.EventQueue$3.run(EventQueue.java:709)
at java.awt.EventQueue$3.run(EventQueue.java:703)
at java.security.AccessController.doPrivileged(Native Method)
at java.security.ProtectionDomain$JavaSecurityAccessImpl.doIntersectionPrivilege(ProtectionDomain.java:76)
at java.awt.EventQueue.dispatchEvent(EventQueue.java:726)
at java.awt.EventDispatchThread.pumpOneEventForFilters(EventDispatchThread.java:201)
at java.awt.EventDispatchThread.pumpEventsForFilter(EventDispatchThread.java:116)
at java.awt.EventDispatchThread.pumpEventsForHierarchy(EventDispatchThread.java:105)
at java.awt.EventDispatchThread.pumpEvents(EventDispatchThread.java:101)
at java.awt.EventDispatchThread.pumpEvents(EventDispatchThread.java:93)
at java.awt.EventDispatchThread.run(EventDispatchThread.java:82)
Caused by: java.lang.RuntimeException: Could not activate rules
at org.languagetool.JLanguageTool.<init>(JLanguageTool.java:183)
at org.languagetool.MultiThreadedJLanguageTool.<init>(MultiThreadedJLanguageTool.java:76)
at org.languagetool.MultiThreadedJLanguageTool.<init>(MultiThreadedJLanguageTool.java:67)
at org.languagetool.gui.LanguageToolSupport.reloadLanguageTool(LanguageToolSupport.java:292)
... 19 more
Caused by: java.io.IOException: Cannot load or parse input stream of '/org/languagetool/rules/en/grammar.xml'
at org.languagetool.rules.patterns.PatternRuleLoader.getRules(PatternRuleLoader.java:76)
at org.languagetool.Language.getPatternRules(Language.java:345)
at org.languagetool.JLanguageTool.activateDefaultPatternRules(JLanguageTool.java:328)
at org.languagetool.JLanguageTool.<init>(JLanguageTool.java:180)
... 22 more
Caused by: java.lang.IllegalStateException: Neither pattern tokens nor regex is set
at org.languagetool.rules.patterns.PatternRuleHandler.createRules(PatternRuleHandler.java:550)
at org.languagetool.rules.patterns.PatternRuleHandler.endElement(PatternRuleHandler.java:324)
at com.sun.org.apache.xerces.internal.parsers.AbstractSAXParser.endElement(AbstractSAXParser.java:609)
at com.sun.org.apache.xerces.internal.impl.dtd.XMLDTDValidator.endNamespaceScope(XMLDTDValidator.java:2054)
at com.sun.org.apache.xerces.internal.impl.dtd.XMLDTDValidator.handleEndElement(XMLDTDValidator.java:2005)
at com.sun.org.apache.xerces.internal.impl.dtd.XMLDTDValidator.endElement(XMLDTDValidator.java:879)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.scanEndElement(XMLDocumentFragmentScannerImpl.java:1783)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl$FragmentContentDriver.next(XMLDocumentFragmentScannerImpl.java:2970)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentScannerImpl.next(XMLDocumentScannerImpl.java:606)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.scanDocument(XMLDocumentFragmentScannerImpl.java:510)
at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(XML11Configuration.java:848)
at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(XML11Configuration.java:777)
at com.sun.org.apache.xerces.internal.parsers.XMLParser.parse(XMLParser.java:141)
at com.sun.org.apache.xerces.internal.parsers.AbstractSAXParser.parse(AbstractSAXParser.java:1213)
at com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl$JAXPSAXParser.parse(SAXParserImpl.java:643)
at com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl.parse(SAXParserImpl.java:327)
at javax.xml.parsers.SAXParser.parse(SAXParser.java:195)
at org.languagetool.rules.patterns.PatternRuleLoader.getRules(PatternRuleLoader.java:73)
... 25 more
I used <token><exception postag="VOA_APPROVED"/></token> and it worked really well. Thank you so much for the suggestion. The inflected and regex are also quite useful.
Can i ask though - the behavior of disambiguation.xml is puzzling.
A. Using a single line of words - this works fine. One issue here is that the second full stop is getting picked up.
a|able|about|above|baby|back|bacteria|bad
B. Two lines of words - So then I tried to break up the rule to put in the exception for the various punctuation marks. Breaking up the words does not seem to work. None of the words got picked up.
a|able|about|above
baby|back|bacteria|bad
C. OR - Using OR does not seem to work either.
a|able
about|above
D. Exception - Similarly, using exception does not work either.
a|able|about|above|baby|back|bacteria|bad
.|,|;
On the above, can I ask:
The STE dictionary you created, is every word in the same <token> tag? How did you handle punctuation marks or do these flag as errors?
Thanks so much.
Tat
P.S. I just discovered the </> button and it is like magic!
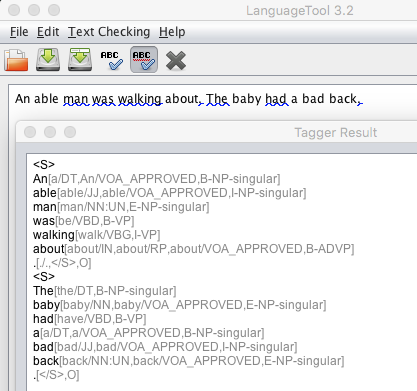
Method A is the correct method. Look at the postags in Tagger Result.The ones that you specified as VOA_APPROVED have that tag.Because you did not specify the punctuation marks as VOA_APPROVED, your grammar rule finds the token. To correct the problem, one method is to include an exception for punctuation marks.
Method B tries to match 2 tokens, the first from the set (a, able, about, above) and the second from the set (baby, back, bacteria, bad). Also, the postag is applied only to 1 token. To apply it to the 2 tokens, use:
Method D. The exception must be on the first token.Currently, you try to match 2 tokens.
For the STE dictionary, there are many different rules to apply the postags. For example, I apply different postags for different types of STE term. Also, each multi-word terms must be in a separate rule.
The STE grammar rule that finds non-STE terms ignores 1-character tokens.