Tiago, I still haven’t had the time to check anything.
Could you do a Firefox add-on pre-AO90?
![]()
Tiago, I still haven’t had the time to check anything.
Could you do a Firefox add-on pre-AO90?
![]()
It would have to be set as a pt-AO locale to avoid reporting conflict. The pre-AO version is also more conservative. It is limited to improvements in gender and number variations.
Good enough?
Any news on this, or on LibreOffice add-on testing?
NOTE: All feedback is welcome. This thread is not an “internal discussion” so all users testing the new dictionary version are welcome to provide constructive criticism.
Sorry… I spent the day coding to fix some issues in the PhD project (software).
Moments ago I installed the OXT in LO 5.3 and here are most of the words that appear as typos in the thesis (most probably already suggested by me to Minho University) (notice that I used M$ Word 2016 pre-AO to write it):
Here are most of the words that appear as typos… again, notice that some may be pre-AO.
As you can see, even I didn’t want to, I had to use M$ Office because the pt_PT speller doesn’t recognise tons of words.
@tiagosantos
I have also tons of false positive grammar suggestions reported by LanguageTool, which I will make a list when I have some more free time.
Thanks for dedicating all this effort and time to the projects.
Well, those are words not included. Not actual dictionary errors. The revision has to be on false negatives, i.e. word derivations included that are incorrect.
Using your examples. If ‘rastreamenta’ (feminin of rastreamento) was considered correct, that would be a dicionary error.
Moreover, most words are foreign words or proper names (foreign or rare). See our replacement tables or the VOP for more information. If you really require them, you can add them to spelling.txt here on LT. Most are barbarisms that you should avoid, and that have no place in a proofreader. See:
Sure. Just try to show the “regular one”. We have daily regression testing, so we can avoid odd test cases like the ones in:
agreement issues with proper names, and false negatives in brands.
Dedidate your time to finish your PhD. I already have people looking into it. Thanks.
Pushed:
For usage examples, see:
Please, keep these thread for all portuguese matters. It is much easier to reference.
Hello @tiagosantos
I have been unable to disable the lowercase suggestion of months and cardinal places:
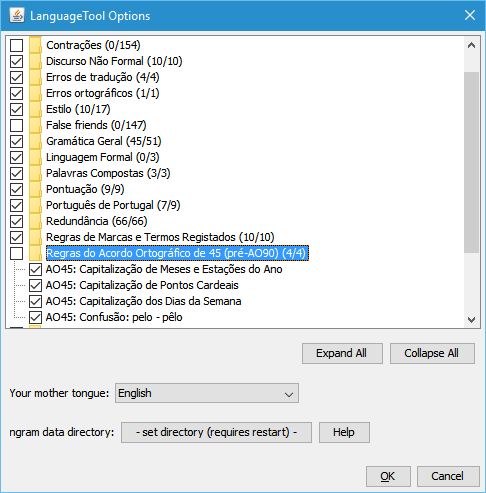
Every time I tick the check box it gets automatically unticked when I return to the settings.
Is there something that can be done?
Thanks!
I can not reproduce this issue. Try ticking the category first and see if it works. I believe this will be enough.
However, if it doesn’t solve, this has to be a Java implementation related bug, not specific to Portuguese.
In this case, the best way is to make a general bug report in GitHub. It might be useful later.
Tiago!
Could you create a rule for “demais” and “de mais”?
I will give you an example of the rings translation document:
“Os anéis ajustáveis são tamanho único. Se, após ajustares a dentição ao limite, os anéis continuarem pequenos demais, remove então cuidadosamente a barra junto do lado liso com uma lâmina afiada e pule a junta com uma lima para as unhas (vê o diagrama).”
I tried using “de mais” and “demais” and I get no suggestion.
I tried the FLIP on-line from Priberam and they too don’t make any suggestion.
PS-> You were right regarding the Capitalization rules. I have been able to remove hits in months names and such.
Thanks!
Kind regards,
Think about the logic and tell the logic that separates both expressions. I will implement it.
This may help:
You’re welcome.
I have been trying to make this rule work but it gives an error when I type: TESTRULES PT
It suggests replacing “montes de” with “imensa(s)” and “imenso(s)”
(informal language/slang).
It simply checks for a VERB + MONTES DE + NOUN.
Could you take a look at my code and make a fix here and there and merge it into grammar.xml?
Thanks!
<rulegroup id="MONTES DE" name="Linguagem Informal - imenso(s) - imensa(s)">
<!-- MONTES DE imenso -->
<rule>
<pattern>
<token inflected='yes' postag="VMN0000"></token>
<marker>
<token>montes</token>
<token>de</token>
</marker>
<token postag="NCMS000"></token>
</pattern>
<message>Substitua por <suggestion>imenso</suggestion>.</message>
<example correction="imenso">Perdi <marker>montes de</marker> tempo.</example>
<!-- MONTES DE imensos -->
<rule>
<pattern>
<token inflected='yes' postag="VMN0000"></token>
<marker>
<token>montes</token>
<token>de</token>
</marker>
<token postag="NCMP000"></token>
</pattern>
<message>Substitua por <suggestion>imensos</suggestion>.</message>
<example correction="imensos">Perdi <marker>montes de</marker> contactos.</example>
</rule>
<!-- MONTES DE imensa -->
<rule>
<pattern>
<token inflected='yes' postag="VMN0000"></token>
<marker>
<token>montes</token>
<token>de</token>
</marker>
<token postag="NCFS000"></token>
</pattern>
<message>Substitua por <suggestion>imensa</suggestion>.</message>
<example correction="imensa">Perdi <marker>montes de</marker> gordura.</example>
<!-- MONTES DE imensas -->
<rule>
<pattern>
<token inflected='yes' postag="VMN0000"></token>
<marker>
<token>montes</token>
<token>de</token>
</marker>
<token postag="NCFP000"></token>
</pattern>
<message>Substitua por <suggestion>imensas</suggestion>.</message>
<example correction="imensas">Perdi <marker>montes de</marker> horas.</example>
</rule>
</rulegroup>Many thanks for this rule, Marco.
The logic is almost correct. The problem is that inflected=‘yes’ only applies to the words inside the token parameter, not inside the tag, nor with the postags.
This: <token inflected='yes' postag="VMN0000"></token> should become <token postag_regexp='yes' postag="V.+"/>.
I believe this will do it. To improve, you can also generelise the Noun. For example, in the first subrule: <token postag="NCMP000"></token> use <token postag_regexp='yes' postag="N.MP.+"/> and it will work with diminutives, aumentatives, superlatives and proper nouns.
By the way, I was able to add one case from the ‘de mais’ ‘demais’ rule, but I believe that is a rare confusion case. Check git for details.
Test if it works as you expected and, if you wish I will push it after testing to the repo.
<rule id='DEMAIS_DE_MAIS' name="Confusão: 'de mais' + 'demais'">
I have just tested it and it seems good 
Tiago, could you commit my rule with your improvements?
Thank you very much!
Kind regards,
I added a new mistranslation rule regarding “medicina tradicional chinesa”.
Do you know if “chinesa” should start uppercase?
Thanks!
Great. That section needs more rules.
What about a rule:
“À minha mãe e ao meu pai” -> “Aos meus pais”
?
There could be more ways of writing it (the redundancy part).
That is a great one. There is already a group that addresses non sexist redundancies, but I believe it doesn’t address that situation. That rule would be a great complement.
Could you create it, please? ![]()
“a minha mãe e o meu pai”
“a minha mãe e pai”
“à minha mãe e ao meu pai”
“à minha mãe e pai”
![]()
![]()
Not on my list of priorities.
Cool, I will do it myself tonight then.
What name should I give to the rule and which category?
Thanks!