Instead of immunizing using the disambiguator, would it not be great to be able to add ‘exceptions’ to the spell checker in a datafile?
Of course, there is ignore.txt which does that for a single token, but maybe it could be expanded to multiple tokens, like:
nota bene , which means bene is accepted when in this combination, but not otherwise. There are a lot of fixed expressions. Of ocurse, the same can be achieved by making a list yourself, and generate disambiguator rules. But this seems more ‘clean’ to me.
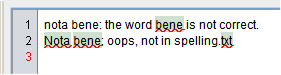
You can add multi-word terms to spelling.txt.(And for English, ‘nota bene’ is in spelling.txt and LT does not give a warning for spelling.)
Yes, but I found bene is alway accepted then, which is not what I need. So I added a rule for that. And there are a lot more words which are only correct in a fixed combination. I would like a simple solution for that.
In fact, I think spellchecking is in itself a less optimal solution. It has only correct vs incorrect, while in fact things are more diffuse. And it only checks single words.
Hi Ruud,
For me, with ‘bene’ alone, LT gives a warning:
I will have to redo the spelling quite a bit, I think.
The great issue is the amount of spacing errors in Dutch.
e.g. ‘spiksplinter nieuw’ is an error of ‘spiksplinternieuw’. I can use replace.txt no to signal the error, which is great. But spiksplinter is not a correct word in itself, so I cannot add it to the spellchecker. But then, the spellchecker signals the error, without a good correction.
Of course I can add it to ignore.txt, but then it is always ignored, which is also wrong.
For it to work completely, I would have to add ‘spiksplinter nieuw’ to the disambiguator to be ignored in the speller. But this is not the only example; there are thousands of this type of error.
Looking from ‘far above’, all LT does is signal errors. But the spellchecker is detecting what is correct, reporting all else as wrong. I guess those to approaches are opposing each other.
