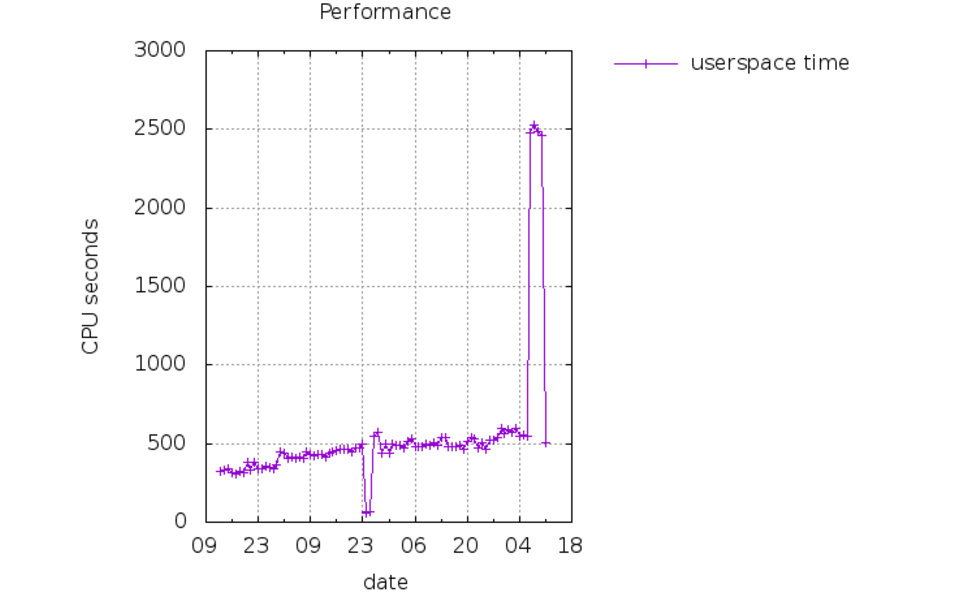
There seems to be a recent change that makes checking Portuguese (PT only) slower by a factor of more than five:
https://languagetool.org/regression-tests/performance-pt-PT.png
@tiagosantos any idea what this is? Can it be improved?
There seems to be a recent change that makes checking Portuguese (PT only) slower by a factor of more than five:
https://languagetool.org/regression-tests/performance-pt-PT.png
@tiagosantos any idea what this is? Can it be improved?
20170506 en 942.21 23.04
20170506 de 591.85 12.09
20170506 fr 457.17 10.68
20170506 ru 149.19 5.22
20170506 br 148.52 5.04
20170506 ca 1062.86 12.81
20170506 pl 695.73 9.67
20170506 it 62.37 3.79
20170506 pt-PT 549.93 10.71
20170506 pt-BR 472.09 9.15
20170506 es 98.43 6.27
20170506 nl 130.98 4.75
20170506 eo 117.20 7.84
20170507 en 936.98 21.44
20170507 de 610.94 12.29
20170507 fr 465.60 11.44
20170507 ru 148.76 5.30
20170507 br 138.63 5.38
20170507 ca 1092.19 14.35
20170507 pl 664.74 11.60
20170507 it 63.68 4.33
20170507 pt-PT 2477.43 29.65
20170507 pt-BR 493.35 10.69
20170507 es 98.24 6.52
20170507 nl 133.59 5.34
20170507 eo 119.19 8.26
From what I have seen, these rules did not have that influence on other languages.
20170507 pt-PT 2477.43 29.65
20170507 pt-BR 493.35 10.69
The main difference is the Dash rule, but that rule had almost no impact on English and Polish.
Database size differences?
I have set it to disabled by default to see if fixes this. Worth checking why it has such impact in pt-PT, anyway.
When lots of data needs to be loaded it should be done only once, storing it in a static variable, for example like here:
Many thanks for the example.
If the default off is not enough I might look into it, but this may be better handled upstream, on the main class.
Setting it to private static final on each of the compound related rules (compounding and dash verification) would duplicate data on memory, right?
I have not looked into the code, but it would be interesting to reused the array in use by the main compound rule that each variant uses. Makes sense?
I’m not sure I understand. Do you mean there’s some overlap in the compound lists of different languages? In general, I wouldn’t care that much about memory usage - if we can speed up LT by using more memory, we should probably do so.
I have only looked at the language binders, so I do not know exactly if the arrays are already being loaded in the main class. I believe there is duplication within the same language, due to this:
public class PostReformPortugueseDashRule extends AbstractDashRule {
public PostReformPortugueseDashRule(Language lang) throws IOException {
super("/pt/post-reform-compounds.txt",
"Um travessão foi utilizado em vez de um hífen. Pretende dizer: ", lang);
–
public class PostReformPortugueseCompoundRule extends AbstractCompoundRule {
private static final CompoundRuleData compoundData = new CompoundRuleData("/pt/post-reform-compounds.txt");
CompoundRuleData is already static final, so making DashRule use the CompoundRuleData set by the relevant CompoundRule may solve duplicated loading.
I use mostly the LO extension, and I couldn’t notice any performace impact, even when reviewing the 1200 pages wikipedia corpus that we used in regression tests (at least on my i7). My version is corrected constatly so I can track what I want to address.
If making PostReformPortugueseDashRule static final is enough to make everyone happy, I am all for it, and I will try it later.
Fixed.
To me, all is great, but if a rule refactor is really required, I may not be the most suitable person to make that kind of decisions.
I’ve just checked this and it’s indeed not the loading time that slows down checking but the fact that a few thousand PatternRules get created. It’s the same effect as adding a few thousand <rule>s to grammar.xml. So I think AbstractDashRule.match() would need to be re-implemented to be faster.
So it was actually both the loading time and the checking time that caused the slowdown. I’ve just refactored the code so loading only happens once.
Many thanks @dnaber.
I will follow other language results and reactivate the dash rule in the coming days.