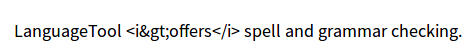There’s a problem with angle brackets in the text both on embedded web-pages and on https://languagetool.org
E.g. if you check the text:
<foreign>HR</foreign>-department
you’ll get back
<foreign>HRforeign>-department
I was able to fix it on my web-page with patch below
diff --git a/sites/default/lt/editor_plugin2.js b/sites/default/lt/editor_plugin2.js
index dabb3f0..3820f8d 100644
--- a/sites/default/lt/editor_plugin2.js
+++ b/sites/default/lt/editor_plugin2.js
@@ -258,7 +258,7 @@ AtDCore.prototype._getPlainText = function(removeCursor) {
.replace(/<br\s*\/>/g, "\n")
.replace(/<.*?>/g, "")
.replace(/&/g, "&")
- .replace(/</g, "<")
+ //.replace(/</g, "<")
// TODO: using '>' still gets converted to '>' for the user - with this line the HTML gets messed up when '<' or '>' are used in the text to check:
//.replace(/>/g, ">")
.replace(/ /g, " "); // see issue #10
It’s a known old bug, but your fix doesn’t work for me… What works for me is commenting in the lines which are commented out, but that leads to other strange issues (like HTML removed completely).
I’ve done a bit more research and it’s a tricky problem: if there are html tags in the text we have two choices:
send them as is to the LT (i.e. < will be sent as <) - this approach has benefit of LT getting original text so it’s analyses words correctly but when the result comes back we need to escape html for the text editor, and with current code that iterates over each error and modifies the whole text it gets messy - that part of the code (markMyWords() function) would have to be rewritten
send html tags to LT already encoded - it would have a benefit of the escaped text being properly marked by LT, but the problem is that currently & is not splitting tokens, e.g. “pott>” is tokenized as one token, so when it’s marked the tags get messed up
BTW currently we do half-and-half: encode > but leave < as is
As first approach is more involving I’ve tried a hack at second, the proof of concept was to replace & with some character that is not part of the token (I’ve used backslash), so with this patch any text with tags that don’t have backslash in it is parsed correctly.
P.S. can we allow .patch extension in the uploaded files on the forum?
diff --git a/sites/default/lt/editor_plugin2.js b/sites/default/lt/editor_plugin2.js
index dabb3f0..4ade4dc 100644
--- a/sites/default/lt/editor_plugin2.js
+++ b/sites/default/lt/editor_plugin2.js
@@ -136,6 +136,8 @@ AtDCore.prototype.markMyWords = function() {
var cursorPos = textWithCursor.indexOf("\ufeff");
var newText = this.getPlainText();
+ newText = newText.replace(/\\/g, '&');
+
var previousSpanStart = -1;
// iterate backwards as we change the text and thus modify positions:
for (var suggestionIndex = this.suggestions.length-1; suggestionIndex >= 0; suggestionIndex--) {
@@ -257,11 +259,13 @@ AtDCore.prototype._getPlainText = function(removeCursor) {
.replace(/<br>/g, "\n")
.replace(/<br\s*\/>/g, "\n")
.replace(/<.*?>/g, "")
- .replace(/&/g, "&")
- .replace(/</g, "<")
+ //.replace(/&/g, "&")
+ //.replace(/</g, "<")
// TODO: using '>' still gets converted to '>' for the user - with this line the HTML gets messed up when '<' or '>' are used in the text to
//.replace(/>/g, ">")
- .replace(/ /g, " "); // see issue #10
+ .replace(/ /g, " ") // see issue #10
+ .replace(/&/g, '\\');
+
if (removeCursor) {
plainText = plainText.replace(/\ufeff/g, ""); // feff = 65279 = cursor code
}
I am testing it on my web-page (I have only Ukrainian module installed there):
You can submit the text like this: <b>десьь</b> <i>тамм</i>
Before the fix the worst happens when you have errors after the mark-up. Here I have two marked up words, both contain typos.
With the original code (and on https://languagetool.org) the check will corrupt the mark-up.
With new code you can see we’re sending encoded html and ampersand is replaced with backslash so LT does not join it with the token: \lt;b\gt;десьь\lt;/b\gt; \lt;i\gt;тамм\lt;/i\gt;
Once it comes back the code will replace backslash into ampersand again and text shows correctly.
I can reproduce that, but I wonder why it doesn’t work for English? Insert <i>your</i> text here. still gets messed up with your fix when I test locally. So the fix depends on the serve-side tokenization?
It looks that the difference is Ukrainian module ignores all Latin words, but English one checks “lt” and “gt” and messes them up. It looks like quick hack of just replacing & does not work.
We have to either teach LT to ignore html escapes (< > & and words inside them) or change markMyWords() function.
Basically we send tags as is (without encoding) but when text comes back we have to encode them in chunks for each text part between rules going backwards (that assumes text inside tags is not checked and not additionally marked by LT): editor_plugin2.js.try2.patch (3.1 KB)
Ok, It looks like the cursor position was restored with span block. This complicates the offset calculation if we escape tags.
I’ve tried different approach, just masking < and > with reserved Unicode characters. The code still works with fairly complex html formatting (I’ve tried rather big block from Wikipedia) and preserves cursor position even inside the tag. editor_plugin2.js.try3.patch (1.6 KB)