gibt es eine einfache Möglichkeit, aus der spelling_custom/added_custom alle Wörter auszufiltern, die auch ohne die Eintragung dort bereits korrekt gefunden werden? Das Problem ist, dass wir aus einer anderen Software eine riesige Liste an nutzerhinzugefügten Wörtern im medizinischen Kontext, davon auch einige bereits in LT bekannte und sehr viele aus bekannten Wörtern zusammengesetzte Wörter als spelling_custom.txt und mit den ebenfalls vorhandenen Grammatiken als added_custom.txt verwenden wollen. Geben wir die ganze Liste hinzu, dann dauern die einzelnen Prüfungen aber viel zu lang, sodass wir eine Möglichkeit finden müssen, die Listengröße deutlich zu verringern, ohne dass dem Benutzer wichtige Wörter verlorengehen.
Eine wirklich ganz einfache Möglichkeit sehe ich nicht. Man müsste mit der Java-API (oder der HTTP-API) ein kleines Script schreiben, das alle Wörter durchgeht und einzeln prüft.
vielleicht gab es hier ein Missverständnis meinerseits, aber ich bin davon ausgegangen, dass hinzugefügte Wörter in der added_custom/spelling_custom von LT genau wie bereits bekannte behandelt werden. Leider musste ich in Nachtests feststellen, dass viele Komposita mit diesen Wörtern nicht korrekt akzeptiert wurden. Das ist unschön, weil wir gerade für die Verkleinerung des Lexikons und die damit einhergehende Laufzeitverringerung alle uns bekannten Komposita aus unseren Teilwörtern ausgeschlossen haben. Da diese einen Löwenanteil ausmachen, würde die Ladezeit mit vollständigem Lexikon viel zu hoch sein. Gibt es eine Möglichkeit, über die Komposita auch aus hinzugefügten Wörtern erkannt werden? Ansonsten bleibt mir nur eine anderweitige Beschränkung des Eingangsmaterials auf die am häufigsten verwendeten Wörter, was aber zu deutlichen Verlusten bei den Nutzerhinzufügungen führen würde.
In der aktuellen Version im git gibt es die Dateien words_infix_s.txt und words_no_infix_s.txt. Wörter, die man dort einträgt, werden als Anfangsbestandteile von Komposita akzeptiert:
words_infix_s.txt - wird nur akzeptiert, wenn ein “s” zwischen den Wörtern steht wie z.B. in Haushaltsführung
words_no_infix_s.txt - entsprechend nur akzeptiert ohns das “s”
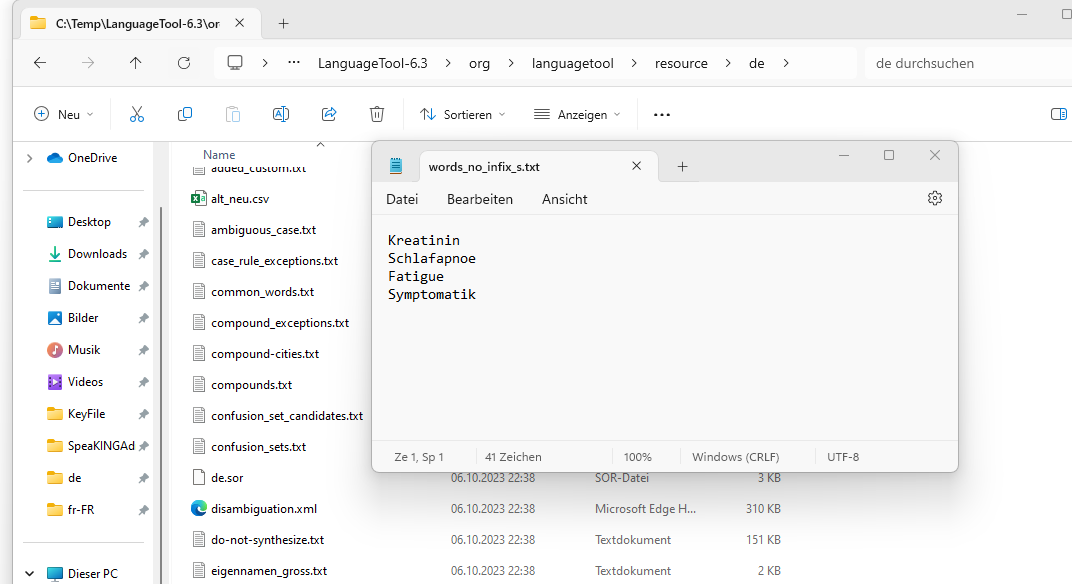
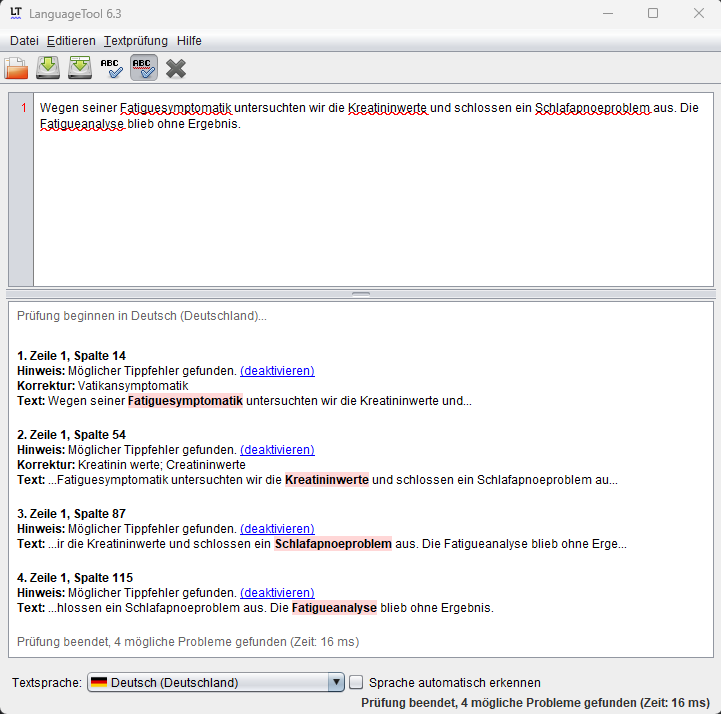
Habe wohl noch einen Denkfehler. Ich hatte als Beispiel folgende Wörter, die nicht als Zusammensetzungen erkannt wurden: Kreatininwerte und Schlafapnoesyndroms. Als habe ich Kreatinin und Schlafapnoe in die Datei words_no_infix_s.txt eingefügt. Dann über die JAR-Datei das LT gestartet und ich musste feststellen, dass beide Wörter immer noch nicht erkannt werden, ebensowenig wie andere Kombinationen mit diesen Wörtern.
Für “Kreatininwerte” kann ich das nicht nachvollziehen, es wird bei mir akzeptiert, wenn ich “Kreatinin” in die words_no_infix_s.txt hinzufüge. “Schlafapnoesyndroms” funktioniert nicht, weil es aus drei Teilen besteht, die words_no_infix_s.txt und words_infix_s.txt wirken nur bei Komposita aus zwei Teilen (und haben noch mehr Logik, um falsche Akzeptanz zu verhindern).
Ich habe die Dateien in der Version 6.3 zwar vorliegen, aber es scheint dort noch nicht zu funktionieren. Anbei die Screenshots meiner words_no_infix_s.txt und die Reaktion von LT auf entsprechende Sätze.