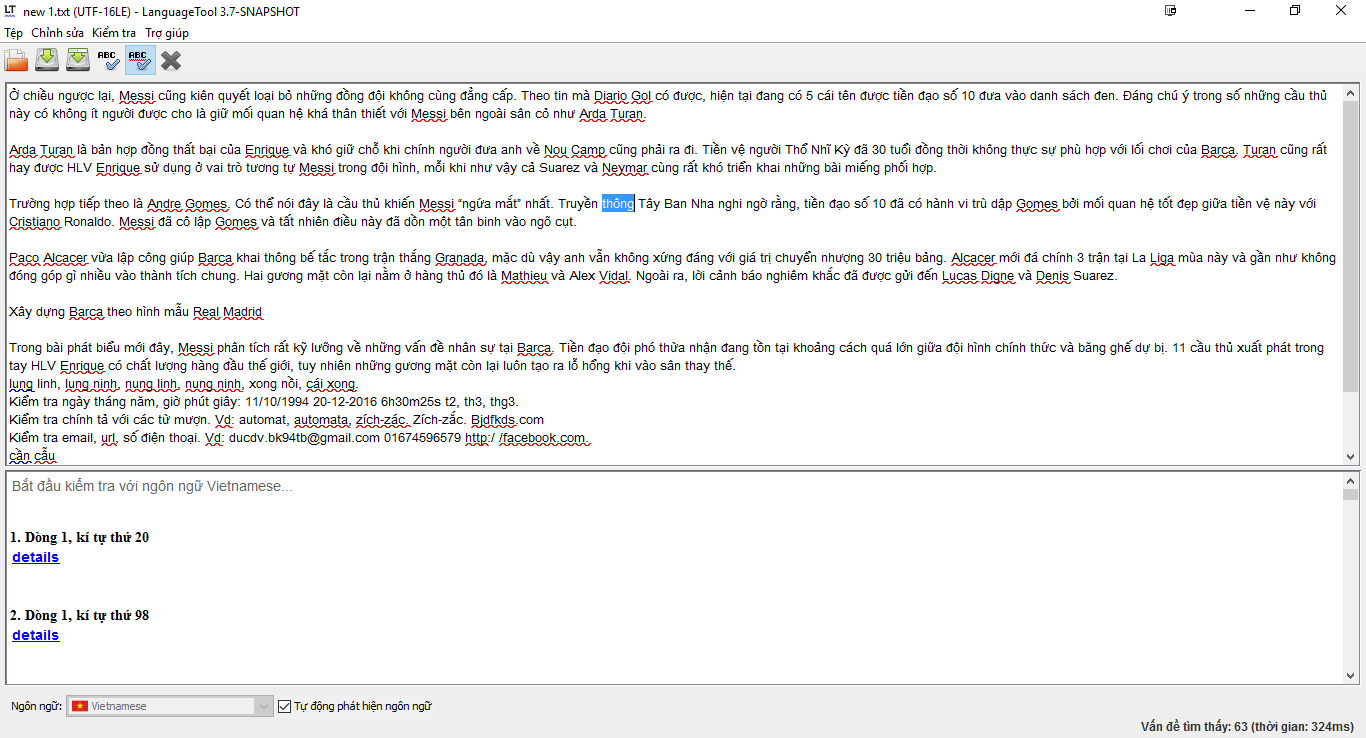
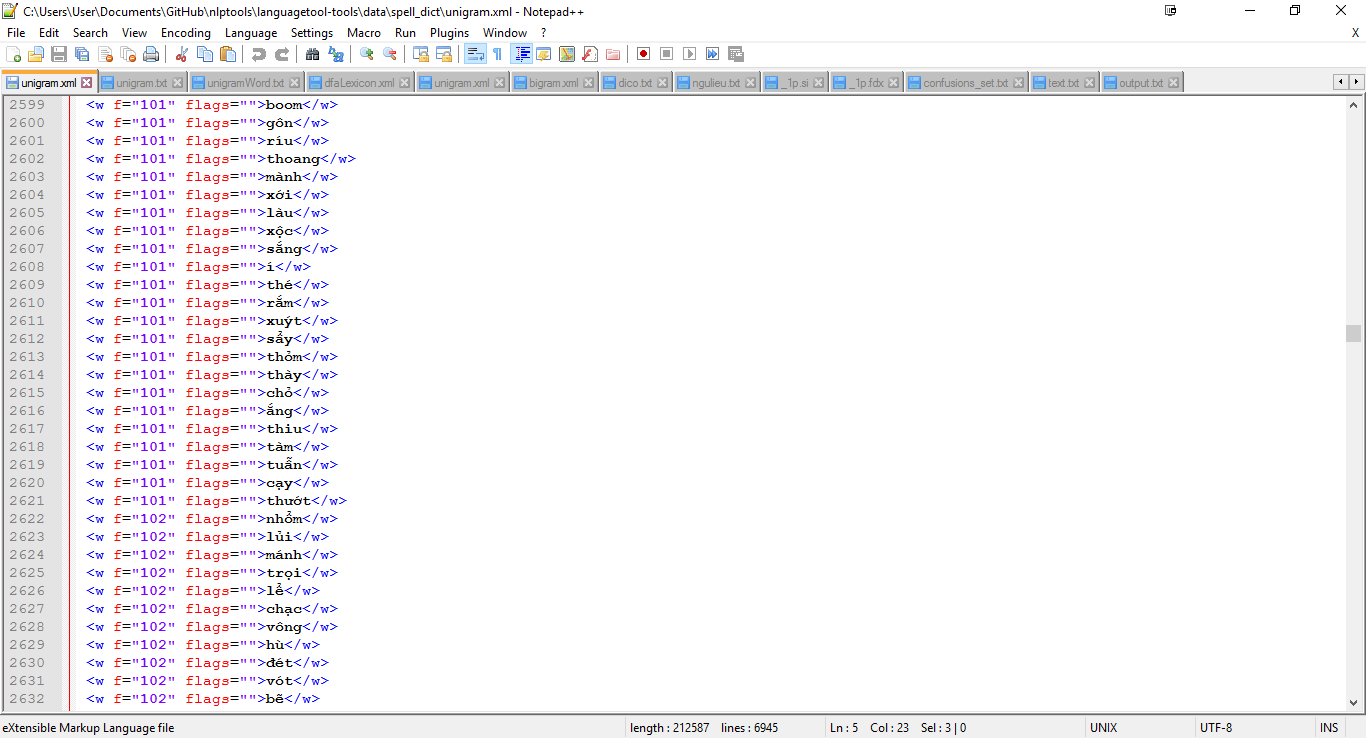
I also have a file grammar.xml for Vietnamese contains >700 rules.
Next, I want to use n-gram to detect real-word error. I mean grammar errors. I tried n-grams to detect error for English like this.
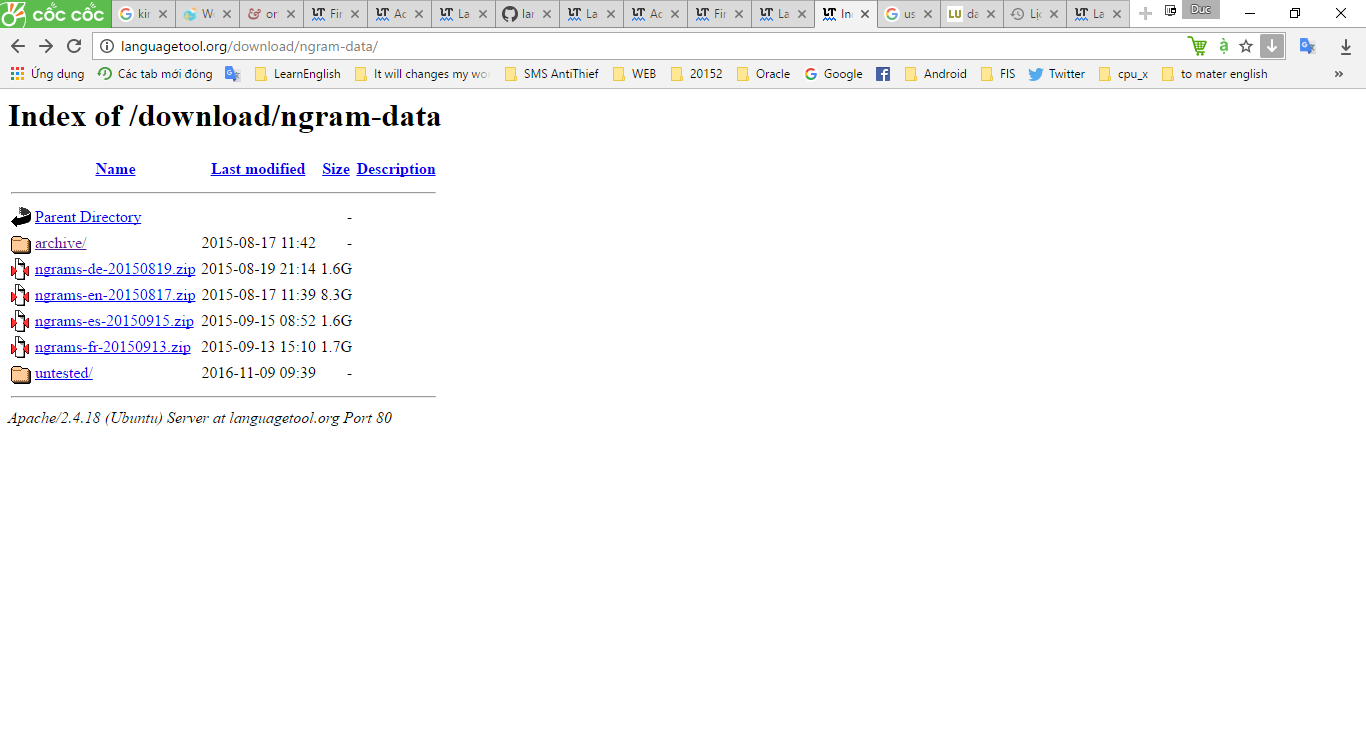
But I can’t find anywhere have n-grams for my language. Anyone can tell me where I can download or how I can make n-grams for Vietnamese like en, de, fr, es. Which is supported by LT.
You will either need a huge amount of text to create the ngrams yourself. Or it might be easier to look for existing ngram sets. You might want to contact universities with linguistic research. A Google search for vietnamese ngram also gets you some results.
Dear Daniel,
Thanks a lot for your suggestion. But I still wonder how LT read my ngram set, have any requires about ngram sets. I mean the structure of ngram so it can be used by LanguageTool.
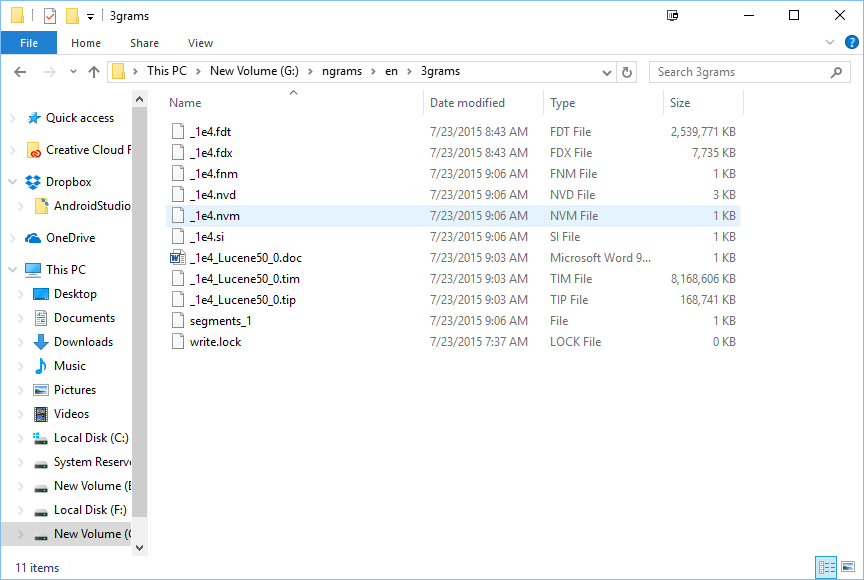
Here is what I see in 3grams directory
It’s a Lucene index with a simple structure, one document per ngram. The ngram field is called ngram, the occurrence count field is called count. There’s also a document with a field totalTokenCount that contains the total token count. You should be able to open the index and look inside using GitHub - DmitryKey/luke: This is mavenised Luke: Lucene Toolbox Project.