I have an annoying problem where my mother language - Bulgarian get’s mistaken for Russian, therefore it tries to correct my spelling in Russian. When I type in English everything works correctly.
I am hosting a local server for Language Tool, but the issue is still there in the cloud based version.
In the options of the browser extension I have set:
Mother tongue: English
Preferred languages (2):
English, Български (Bulgarian)
(Checked) Always only use these languages for automatic language detection
To reproduce the behavior you can use this test sentence: “Здравей! Как се казваш? Искаш ли днес да говорим?”
Is there any way I can fix this? It becomes really annoying when typing in Bulgarian. Sometimes I mistake the suggestions for genuine and click to accept them, only for it to change the already correct word to an incorrect one (At least in Bulgarian).
Thanks for the report. I can’t reproduce this locally. Have you set fasttextModel and fasttextBinary in your server.properties file? This should improve language detection. Anyway, I wonder why it fails in the cloud. @SteVio1989 Have there been any issues with FastText recently?
This is what it looks locally for me (with FastText configured):
With less than 50 (the sentence has 49) characters, ngrams and not fast text are used by the DefaultLanguageIdentifier. @dnaber do you have configured the lang-detect ngrams locally? ngramLangIdentData property in config file.
Sorry, I forgot about that. @MrPetrakiev our ngram data hasn’t been trained on Bulgarian IIRC, i.e. it never suggests it, not even with “Always only use these languages for automatic language detection”. I don’t know an easy fix for that.
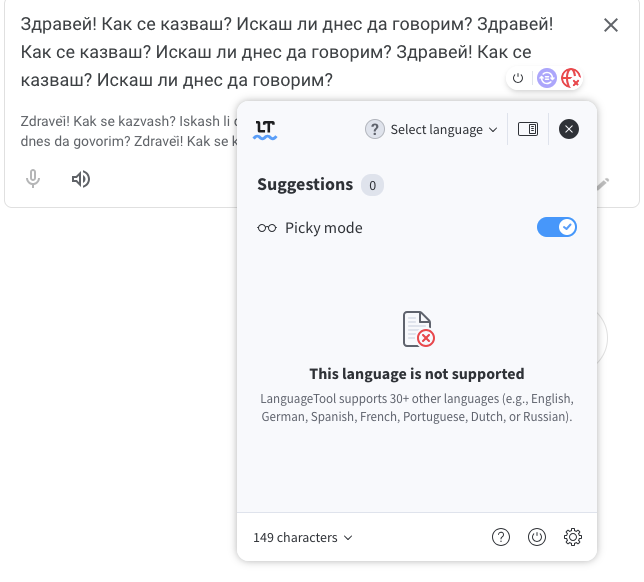
While using the cloud server, then pasting the sentence:
Здравей! Как се казваш? Искаш ли днес да говорим? Здравей! Как се казваш? Искаш ли днес да говорим? Здравей! Как се казваш? Искаш ли днес да говорим?
(Pasted 3 times repeatedly to make the character count larger then 50 characters)
I was able to get the message “This language is not supported”. Not trying to type out a larger sentence in Bulgarian while using the cloud server to test it, was a mistake on my end. It works as expected while using the cloud version.
While using my self hosted server, I have the issue no matter how many characters I use. I am unsure how to setup fasttextModel or fasttextBinary in server.properties as I have set up the server as a docker container, which I think was not officially supported. When I try to look in the files of the docker container, it doesn’t have a file server.properties. Instead it has a config.properties file which includes only paths to the ngram files.
The full list of files and folders included in the docker container are:
I am unsure if there is even a way to fix it even if I were to use the official method for installation, as you mentioned in your last message that Bulgarian data is not present in the ngram training data.
You could ask the vendor of the docker to include FastText. java -jar languagetool-server.jar will give you a short help about the options in the file. config.properties is probably the same as server.properties. fasttextModel and fasttextBinary are just paths to the FastText model and Linux binary (you might need to compile it).