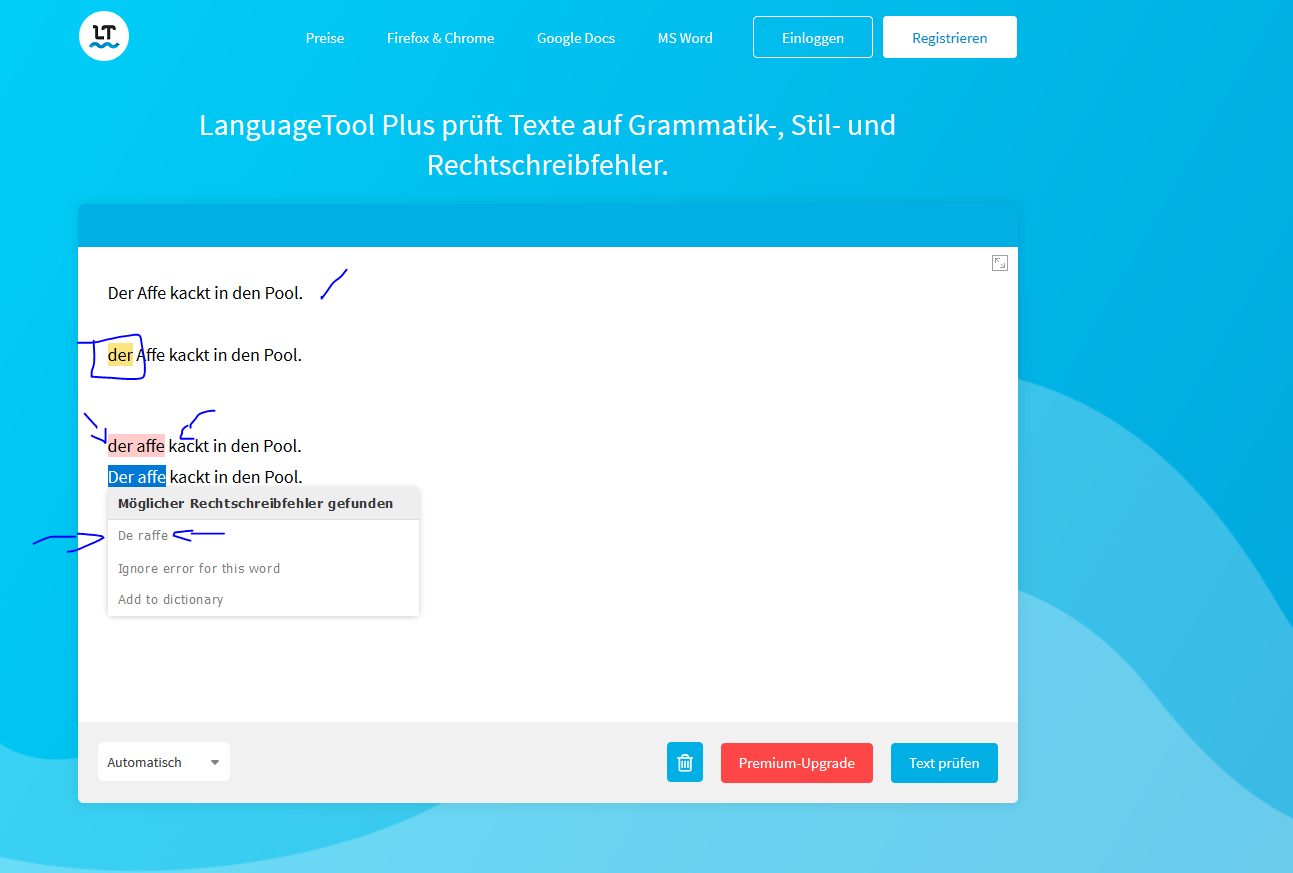
Danke, ist leider kurzfristig nicht so einfach zu beheben, ohne dass andere Fälle schlechter behandelt werden…
This seems like an even bigger problem in Portuguese (Brazil):
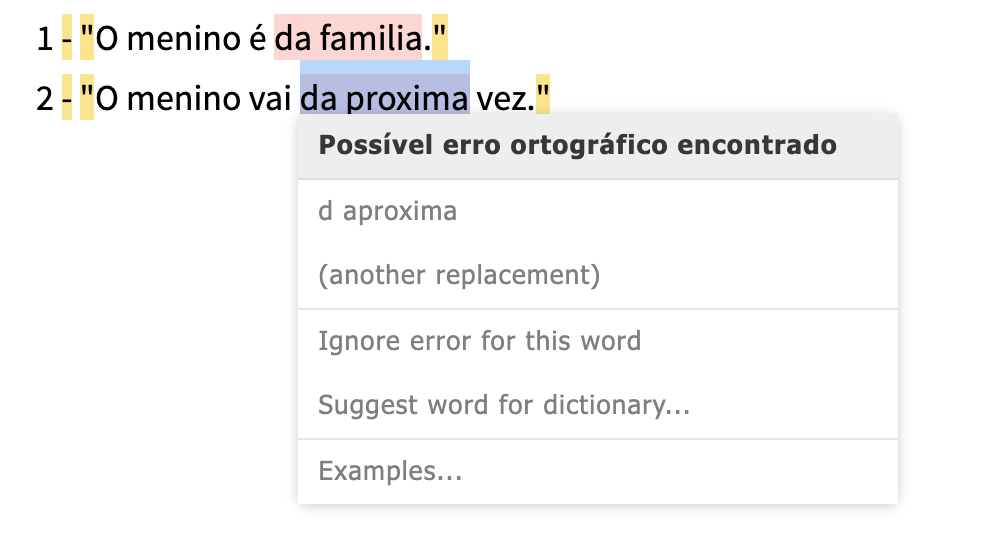
The only word not correctly spelled is: “proxima” (should be “próxima”, with an accent)
Interestingly this doesn’t happen with Portuguese (Portugal)
I tried to mitigate problems like these showing more suggestions when one of the two words is very frequent. The same could be done when one of the words is very short. I will make some adjustments. If you have more examples, please post them here.
@jaumeortola @dnaber I’m updating this issue with more user feedback:
Is there a way that we can disable the optimizations we recently did for Brazilian Portuguese? I don’t know why but Portugal Portuguese isn’t affected by this.
As for German, one thing to do is to copy the last changes in MorfologikSpellerRule.java into HunspellRule.java.
Portuguese also uses a Hunspell spelling rule.
The difference between Portugal and Brazilian Portuguese is probably because their Hunspell dictionaries are different. “d” is in the Brazilian Portuguese dictionary (so that “d afamilia” is an allowed suggestion), but it is not in the Portugal Portuguese dictionary.
To improve the suggestions, in the Morfologik spelling rule I used the word frequency that is stored in the Morfologik dictionaries. Is this information available anywhere for languages using the Hunspell spelling rule?
I don’t think it’s available programmatically if you only have hunspell. We use gaia/apps/keyboard/js/imes/latin/dictionaries at master · mozilla-b2g/gaia · GitHub but this gets baked into Morfologik dicts. In some cases, we also use the ngrams, i.e. the 1grams, but that’s not available yet for Portuguese…
“der affe” can be easily fixed adding an exception for capitalized words: if there is a capitalized version of the word, the split suggestion is unnecessary. This can be valid for any language.
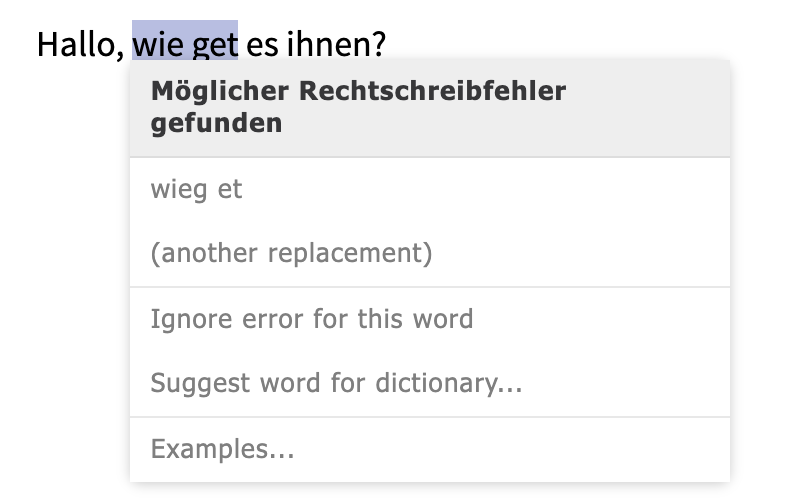
In the rest of cases, we can generate more suggestions when the correct word has few characters (1 to 3), like wie, der in German, or da in Portuguese. For da familia we will generate d afamilia but also da família and da familiar.