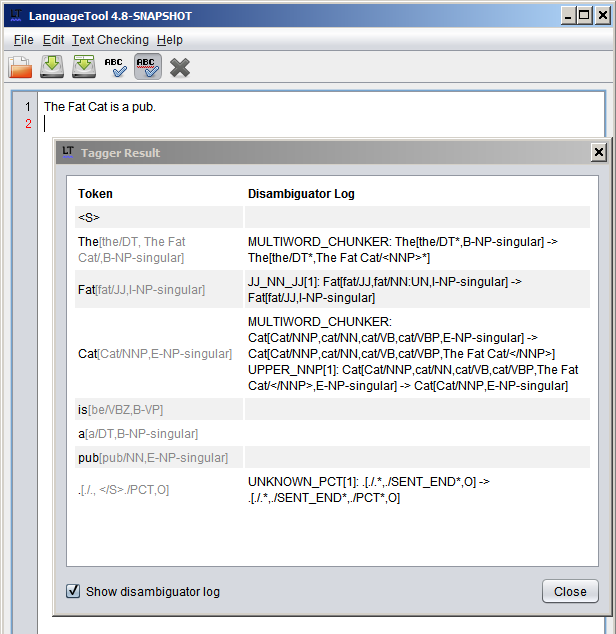
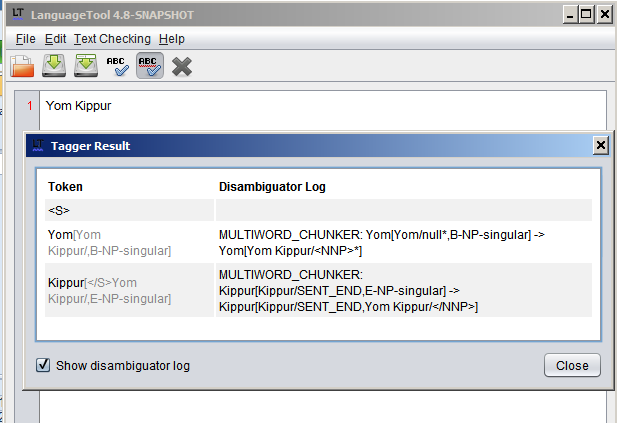
The multiword chunker removes DT from The and all the readings except NNP from Cat. I guess it also removes readings from Fat, but I cannot see that.
Disambiguation JJ_NN_JJ applies JJ to Fat. For test purposes, I thought to put an antipattern on the rule to prevent the rule from changing a multi-word proper noun. But, the rule has this example: <example type="ambiguous" inputform="Canadian[Canadian/JJ,Canadian/NNP]" outputform="Canadian[Canadian/JJ]">The <marker>Canadian</marker> Badlands is nice.</example>
As it happens, Badlands is NNP, thus an exception for a sequence of 2 proper nouns would mean that in this context, Canadian is not disambiguated as JJ. I think that it should not be JJ, but rather, the correct disambiguation is to make Canadian Badlands a proper noun. (Rule NNP_NNS_VBZ_NNP applies NNP to Badlands.)
If a term is a multi-word proper noun, should a disambiguator rule that changes only a single token change the NNP postag?
I don’t plan to change any rules at this stage, but I would like comments/suggestions from the team about what the correct analysis is.
Neither testrules nor the Maven tests give a warning about the comment. Thus, I guess that multiwords.txt can safely contain a comment on the same line as the term. Can you please confirm that it is OK to add a comment on the same line?
I don’t know, I have just activated multiwords.txt the same way (I think) it works for other languages. Maybe @jaumeortola can comment - ca/mulitwords.txt seems to be well-maintained.
In a multiword of 3 or more tokens you will get tags only in the first token and the last one.
To match these tags you need patterns like <token postag=".*NNP.*" postag_regexp="yes"/> or similar.
We could add options to the MultiWordChunker to get other tags. Instead of <NNP> </NNP>, you could get just the tags NNP NNP, even in the in-between tokens in multiwords of 3 or more tokens. We could also remove optionally all other tags (existing for individual tokens if they are in the tagger dictionary). These options are not yet implemented.
An existing useful option is to ignore spelling errors in all tagged words. That’s one of the main functions of the multiword list in Catalan.
Your screen shot of the command line shows the result that I expect.
So, I think that the Tagger Result shows incorrect information. If you agree, let me know, and I will open an issue (or you can do it).
My idea was to use multiwords.txt to apply NNP postags to multi-word proper nouns, because the current method of adding the proper nouns to disambiguation is cumbersome. (Also, currently, the rules are at the end of disambiguation.xml. Probably, if they remain in disambiguation, they should be at the top of the document. The postags for 1-word terms are available to the disambiguator, but postags for multi-word terms are not available.)
How do you achieve that? Multiwords can also be added to spelling.txt, but that seems to have a bad influence on performance if the list is too long. How about this solution for a very long list?
Do you mean “ignore all tagged words”? It is an option of the MorfologikSpellerRule. In Dutch, it is disabled now. If you want, I can enable it for you.
It is only of use when there is no significant performance effect when adding wordgroups to multiwords.txt, and since that is a text file, like spelling.txt, I am not to sure about that.
And I am not sure about ignoring all tagged words either.
So thanks, but no, thanks for now.