Someone asked me whether there’s a tool that can detect the usage of nouns that don’t match people’s names in Russian. Being a frequent LanguageTool user, I immediately thought of giving it as an example, but when I actually tested it, I was surprised that there doesn’t seem to be such a rule in any of the languages in which I can test it.
Such a rule would be relevant for English, too: “Mary was a king. Ann was an actor.” And in some other languages:
- Russian: “Мария была королём. Анна была актёром.”
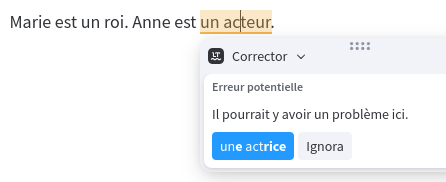
- French: “Marie est un roi. Anne est un acteur.”
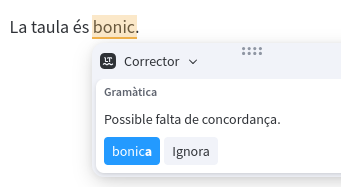
- Catalan: “Maria era un rei. Ana era un actor.”
In French and Catalan, LanguageTool correctly identifies the lack of agreement between the article and the noun. Catalan, for example, will complain about “una actor” (the correct thing is “una actriu”). But it doesn’t complain about the fact that “Maria” and “Ana” are common names of women, but the noun in the sentence doesn’t match their gender.
Is there a particular reason why this wasn’t implemented? For example, a specific technical or social motivation to avoid it?
Or is it just a rule that can theoretically be made, but no one ever got around to doing it?
Does such a rule, perhaps, exist in any other languages that I didn’t mention?