Hi there,
I’ve been practicing using the Naive Bayes with Weka and Python. I decided to try out the algorithm to create a comprehensive grammar checker. I’ve noticed recently that the grammar checkers of MS Word, LibreOffice, Grammerly, Ginger, et cetera, actually miss around 80-90% of grammar errors. This is amazing as it seems like a great opportunity to create the best grammar checker available.
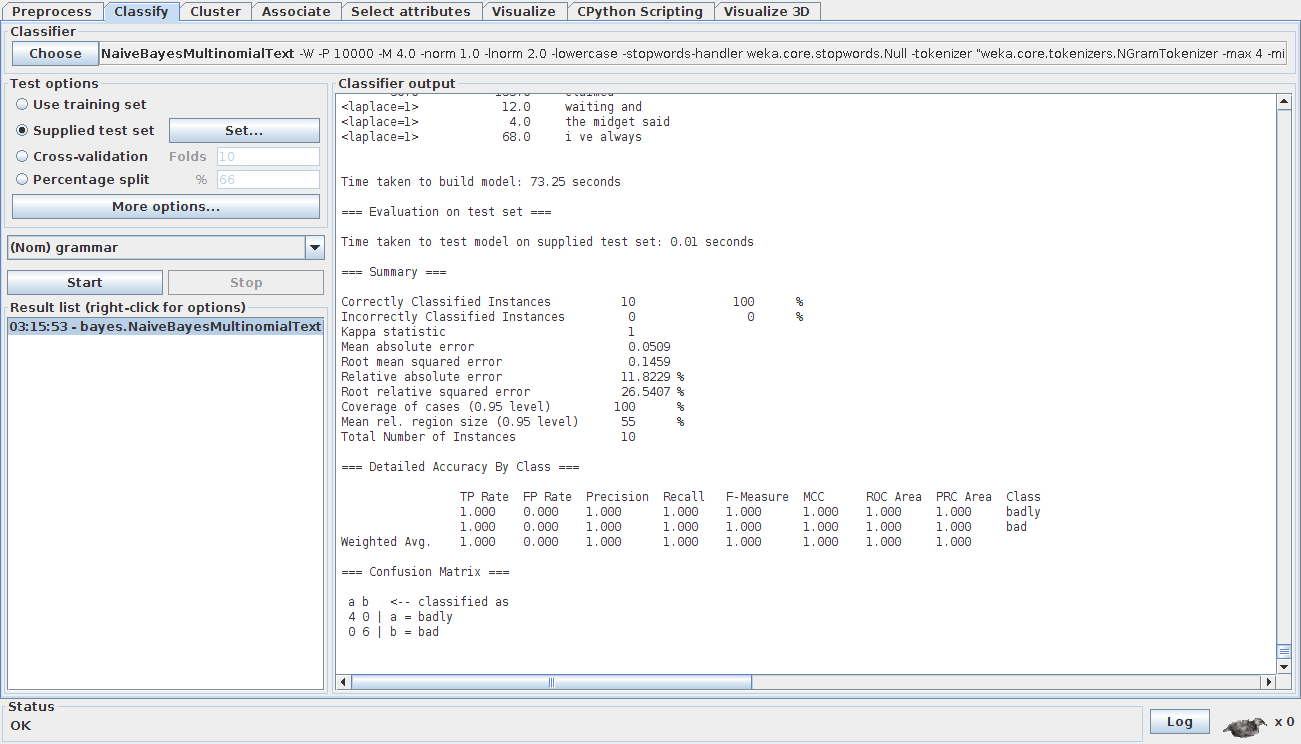
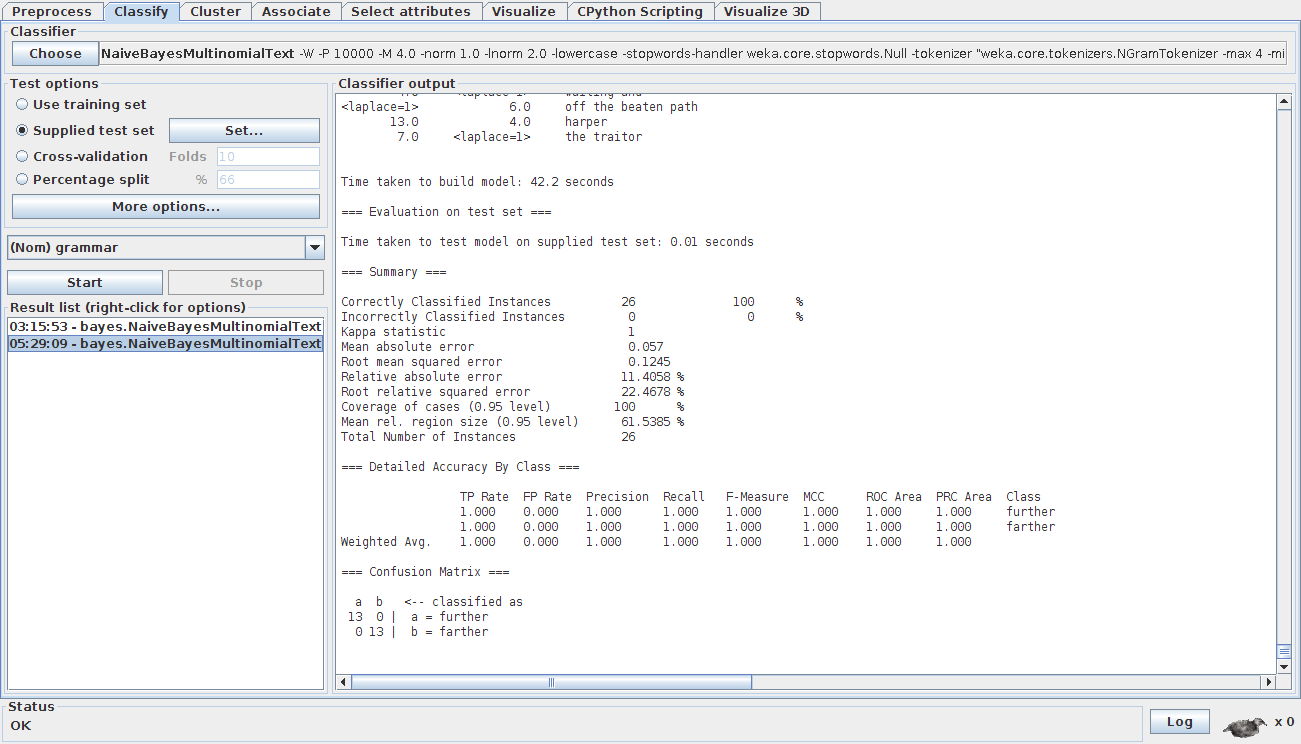
So, I decided to use Naive Bayes to create a simple grammar checker for a single rule. I used the rules for ‘further vs farther’ because MS Word was unable to detect when these words were misused.
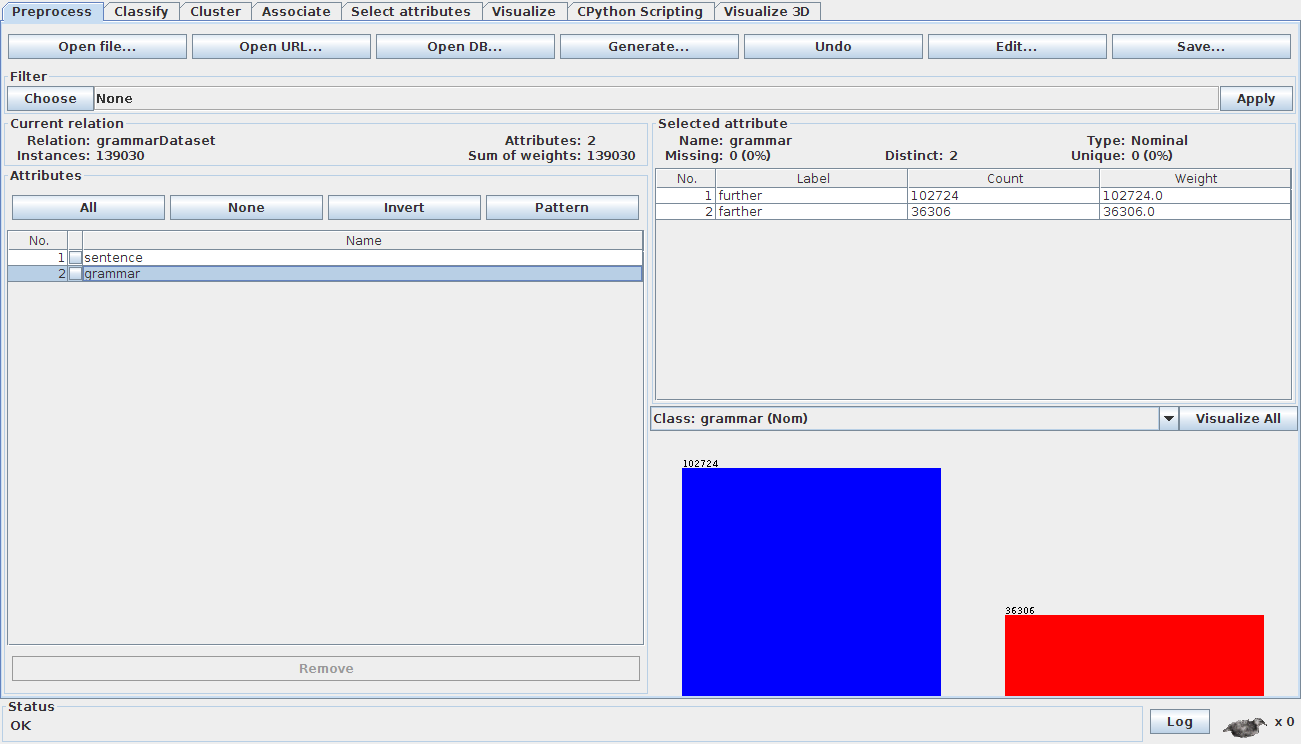
At first I collected word tags (e.g. NNP, VB, NN) surrounding a key word, to see if I could tap into patterns. I used a Gutenberg corpus of many books (n = 595). I didn’t get great results, so collected words from either side of a key word. I didn’t want to do this at first because it will take up a lot of space, but it worked well. Yet my grammar checker was still getting a lot of false positives, especially for ‘farther’ sentences. When I looked at the Gutenberg books, I noticed that many of the authors were misusing the words further and farther. I did a bit of research and found out that the distinction between the two words has changed in recent years and thus an old corpus will probably be less accurate. Thus, I downloaded a modern corpus of new release books (n = 7976) in the hope of getting better results. I conducted the Naive Bayes with each word being either true or false in positions 2-left, 1-left, 1-right, 2-right of the main keyword. I got 90% + accuracy for the word ‘further’ and 70%+ for the word ‘farther’. I looked at the data and noticed that some authors were misusing the word ‘farther’. For example, one author wrote: “He’s running trying to reach me but he’s getting further away”. This should be ‘farther’ as it is talking about a physical distance. Despite using a corpus of ‘published’ authors, I still find such errors. Such errors in the data distort the results a bit. I will currently try to fix this by including more books and by fixing errors as they pop up.
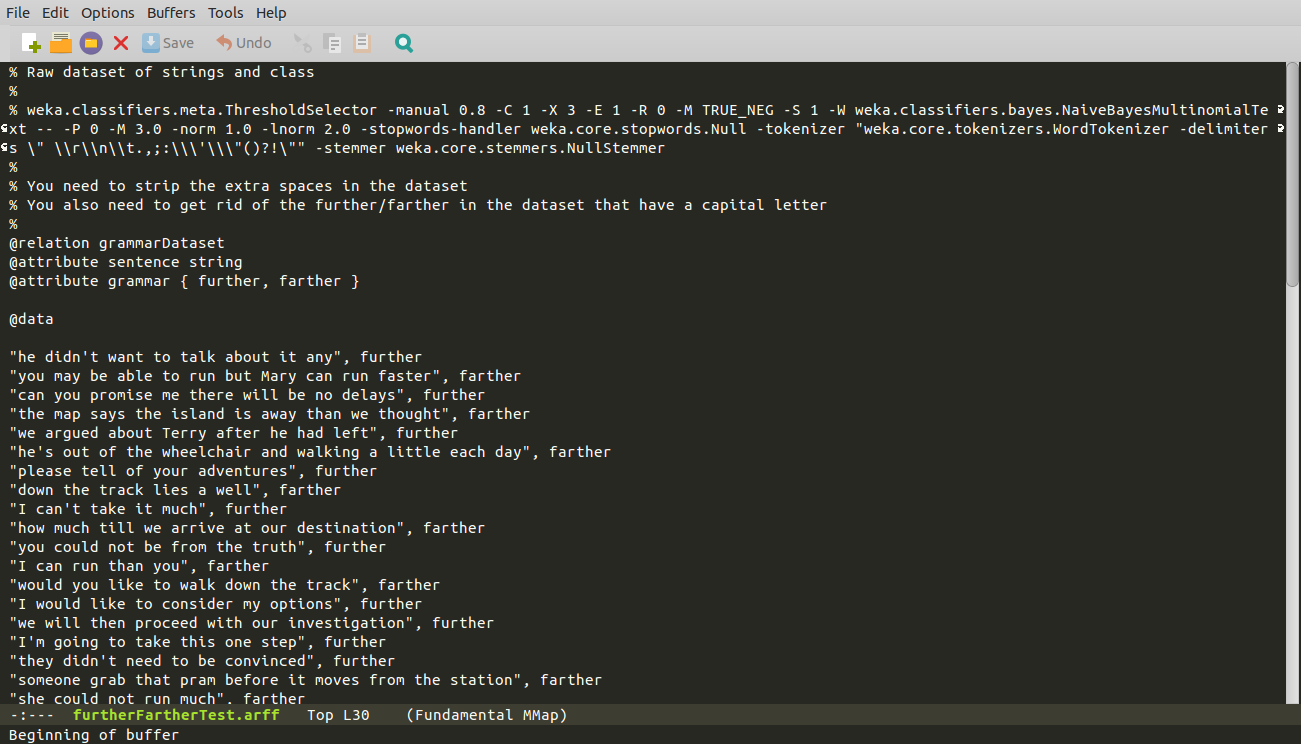
Here's my data format:
For the sentence: “You need look no further than our very recent history to see that it has been the Dark Jedi that have sought isolation”.
I extract this info: [look, no, than, our, further]
As you can see I extract words surrounding the key word, and I put the class [further | farther] at the end.
Here are some live example of me testing my Naive Bayes probability file:
I need to run farther than Mary.
0.334873568382 [further], 0.665126531618 [farther]
Without further issue, we must take action.
0.998243358719 [further], 0.0017566412806 [farther]
If you complain further, I’m going to shoot you out of the airlock.
0.9210218447 [further], 0.0789781552999 [farther]
Making people park a little farther away will actually increase their exposure to danger.
0.388846474458 [further], 0.611153525542 [farther]
Amazing isn’t it! As you can see, it was able to correctly correct the grammar of all of these sentences.
If this single rule grammar checker works well, I will iterate over a list of 100-200 word daichotomies to create a fully functional grammar checker that picks up on errors that no other grammar checker on the market is able to pick up onto. I’m using Python to write up my scripts, but any language could access my Naive Bayes probability tables.
I have used Weka to load in the data, but I don’t like the @attribute tags because they take up a lot of space if I have to add every word used to each tag. I’d rather just announce the words used once and reference each list for the @attribute tags. Is this possible? Otherwise, the ARFF format is going to be a problem for conducting document analysis.
Troy