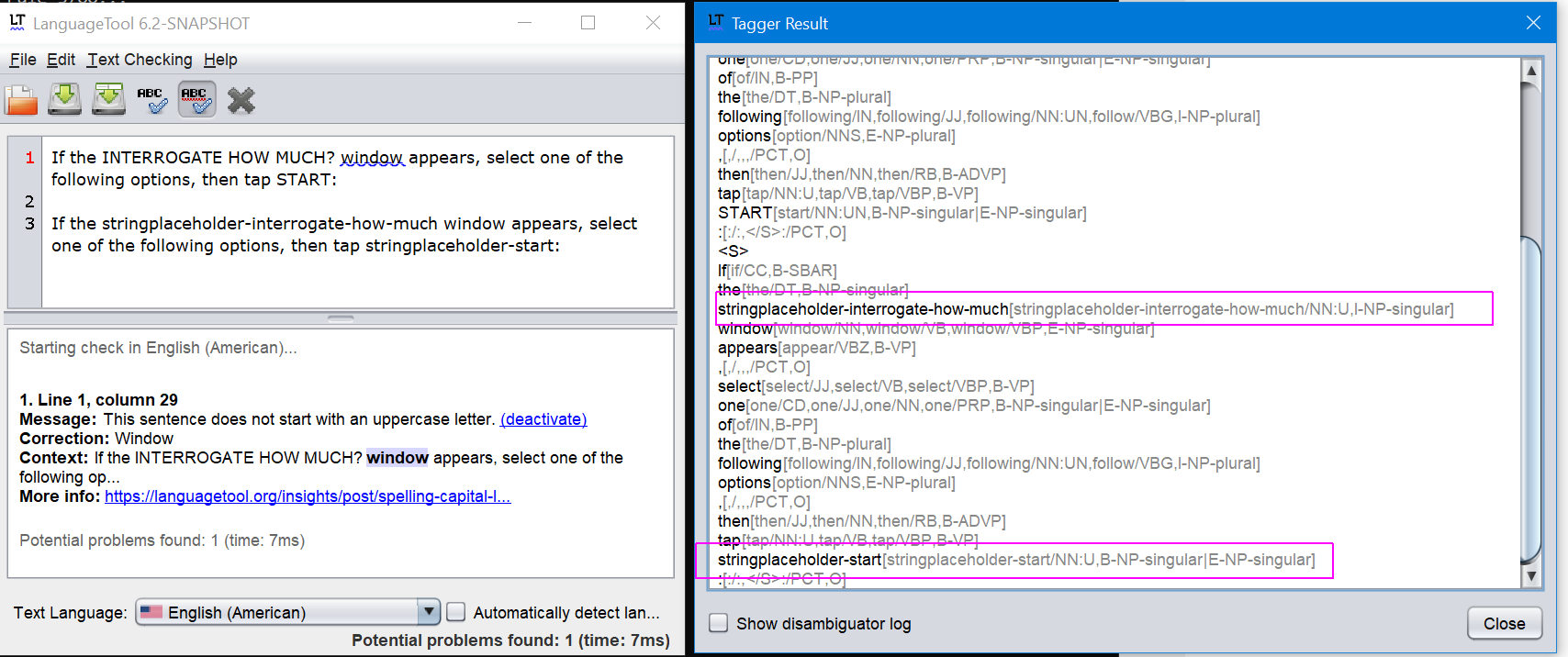
We are getting quite a few hits related to software string references when they are used in the middle of a sentence. For example:
“If the INTERROGATE HOW MUCH? window appears, select one of the following options, then tap START:”
Language Tool thinks this is 2 sentences, because of the ? in the string. There are some others where it doesn’t think it’s 2 sentences, but still has trouble with the string because of agreement or something. The hits would be legit hits, if they weren’t software string references that need to exactly match the UI. We do have markup tags available to us, so we could preprocess these in some way. Has anyone else run into this situation and if so, how did you handle it?
Is this about a local or company server, or the public LT?
Is writing these references capitalized a general rule?
If so, the srx file could have an exception for [A-Z]{2,8}[?] before [a-z]
We are using a company server. The software references are not generally capitalized. It is completely dependent on the product’s user interface, so we often see a mix of title case, all caps, special characters, etc.
We would prefer a way to preprocess our existing XML markup. An example of such markup for a software reference, indicated by the <literal> element:
<note><para>Except for use of the <literal type="button">Emergency</literal> button or the <literal type="button">Stop</literal> button, you cannot proceed with session activities until the initial interrogation is 100% complete.</para></note>
Or - What could we replace the software reference with in order to not have the gap flagged? For example, “Press PRINT to see the output” → “Press to see the output”
What we are looking for is guidance surrounding a strategic/practical decision. What have others done with their software strings to prevent noise hits? We have full control over our markup so the problem is not how to remove them. We’d like to better understand what others have done in the same situation.
Is there a strategy people have used to reduce ‘noise’ hits from the grammar rules?
There are 2 common sources of noise hits I see:
Software strings in the middle of a sentence. examples: (bold text shows items set aside by markup specific to software strings)
To gather all of the information from the device, select the All option.
The Interrogate… and End Session… buttons do not appear on the Emergency screen.
Select or clear the Clipping, ECG Filter, and Show Artifacts check boxes as desired.
If the Interrogate How Much? window is displayed, select Interrogate All to save a record of all the information from the device. (this one actually flags “window” as a start of sentence without capitalization)
Feature names. Often capitalized, and used in the middle of a sentence. They aren’t necessarily spelling hits. They are not marked up. examples:
Atrial ATP therapies are Burst+, Ramp, and 50 Hz Burst, each with a programmable number of sequences.
The Initial #S1 Pulses parameter sets the number of pulses in the first Ramp sequence.
How are other people handling these type of situations? We would prefer not to obliterate them, as they may have typos in them. but… they do produce A lot of noice in some of our docs.
In disambiguation.xml (or your external disambiguation file), specify each placeholder as a non-count noun (if you use the term as a non-coun noun or a proper noun), and ignore the spelling:
Thanks for that information. We haven’t used that disambiguation file to date, but I see how it would work.
While experimenting, we ended up stumbling on an easy solution that preserves the ability to have it check for spelling mistakes in the strings: simply wrap every string reference in double quotes. LT seems to recognize it as perhaps a quoted sentence, and applies different rules. We don’t get any more grammar hits for having a capitalized word in the middle of a sentence, or for not capitalization after a ? mark, when the ? mark is part of a string. If there are typos though, in the string, it will still report them.
In the screenshot, there is still one hit, for a string consisting of “All”. In this case, however, the writer failed to markup “All” as a string, so the quotations are not applied, and you get a noise hit. Perfectly fine (good, in fact!). Writer needs to apply the correct markup. All the other strings on this page were causing noise hits before, now they are all passing. Under the hood, what LT sees is:
At the start of the patient session, the programmer interrogates the device. You can manually interrogate the device at any time during the patient session by performing the following steps: Select “Interrogate…” from the Command bar. In a nonwireless session, you can also interrogate the device by pressing the “I” button on the programming head. To gather information collected since the last patient session, select the Since Last Session option from the interrogation window. To gather all of the information from the device, select the All option. Select “Start”.
I’m not 100% sure why LT doesn’t flag “Since Last Session”, as that doesn’t look like it has any markup either.
Anyway, in case anyone else is struggling with the same question, that’s how we solved it.