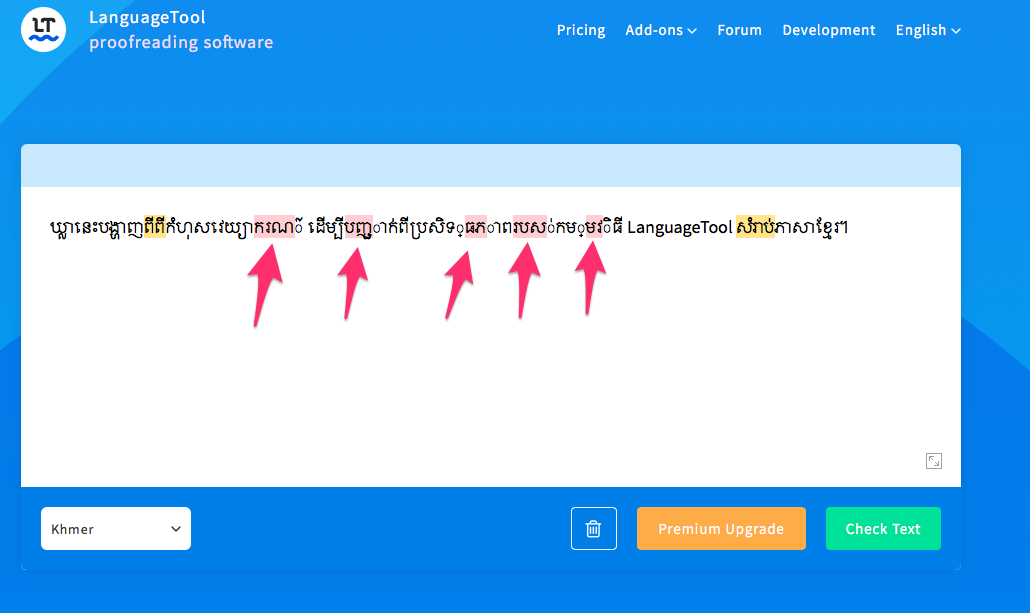
Khmer doesn’t have spaces, so with Unicode we add a zero-width space (U+200B) between the words so a spelling checker can know where the word boundary is (as well as line-break correctly).
Is there a way I can help fix this? The sentence should be broken like this:
ឃ្លា នេះ បង្ហាញ ពី ពី កំហុស វេយ្យាករណ៍ ដើម្បី បញ្ជាក់ ពី ប្រសិទ្ធភាព របស់ កម្មវិធី LanguageTool សំរាប់ ភាសាខ្មែរ។
(but with zero-width spaces, not real ones).
I believe we had it turned off in the LibreOffice extension since we use Hunspell for Khmer.
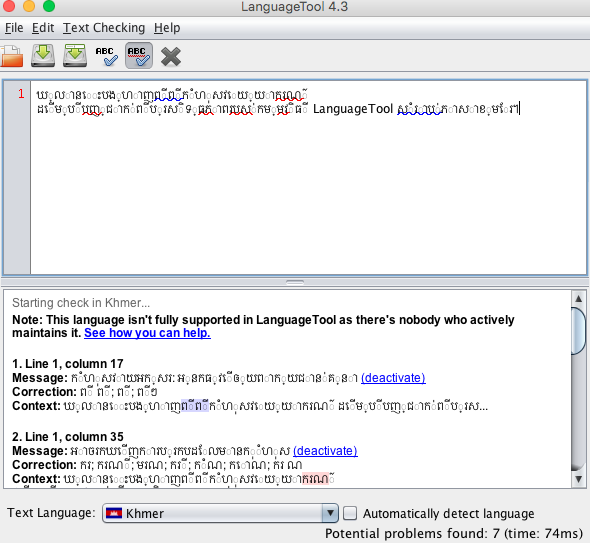
But looks like it doesn’t work in the Java application on a Mac either (in fact Khmer doesn’t display correctly at all).
Could you lead me to the java class in which is responsible for Khmer tokenizer? I have the same issues. LanguageTool detects handful errors on correct text. At the moment, the string tokenizer for Khmer confused incomplete sentences or a cluster of vocabularies with missing characters as a token.