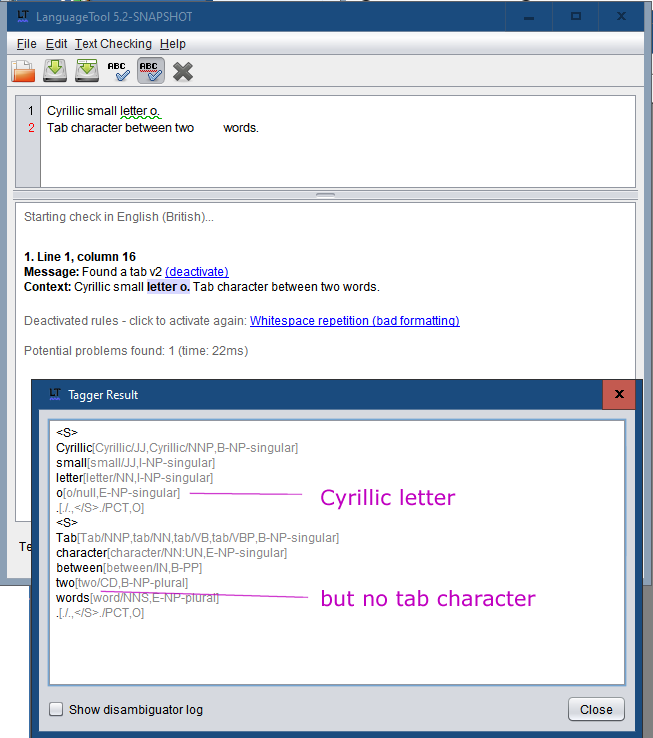
I would like to make rules that find the tab character in some contexts. Is it possible, and if yes, how?
This rule partly works:
<rule id="TAB_CHARACTER" name="Find a tab character">
<regexp>	</regexp>
<message>Found a tab</message>
<short>Tab</short>
<example correction="">A tab character: a<marker>	</marker>b between a and b.</example>
<example>No tab character.</example>
</rule>
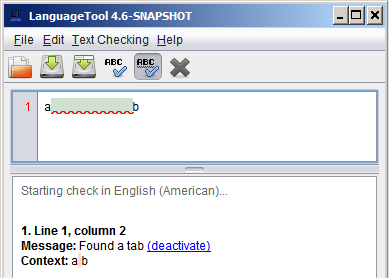
But, testrules gives this warning:
Running pattern rule tests for English... Exception in thread "main" java.lang.AssertionError: English rule TAB_CHARACTE
R[1]:
"A tab character: ab between a and b."
Errors expected: 1
Errors found : 0
Message: Found a tab
Analyzed token readings: [/SENT_START*] A[a/DT*,B-NP-singular] [ /null*] tab[tab/NN,I-NP-singular] [ /null*] character
[character/NN:UN,E-NP-singular] :[:/:*,O] [ /null*] ab[ab/null,B-NP-singular|E-NP-singular] [ /null*] between[between/
IN,B-PP] [ /null*] a[a/NNP,B-NP-singular] [ /null*] and[and/CC,I-NP-singular] [ /null*] b[b/null,E-NP-singular] .[./.
*,./SENT_END*,O]
Matches: []
Regexp:
at org.junit.Assert.fail(Assert.java:88)
Also, the right-click menu does not work fully.
W3C Schools (W3Schools Tryit Editor) shows 3 ways to represent the tab character in HTML. If I use 	, testrules gives this warning:
Exception in thread "main" java.io.IOException: Cannot load or parse '/org/languagetool/rules/en/grammar.xml'
at org.languagetool.XMLValidator.validateWithXmlSchema(XMLValidator.java:123)
at org.languagetool.rules.patterns.PatternRuleTest.validatePatternFile(PatternRuleTest.java:214)
at org.languagetool.rules.patterns.PatternRuleTest.runTestForLanguage(PatternRuleTest.java:146)
at org.languagetool.rules.patterns.PatternRuleTest.runGrammarRulesFromXmlTestIgnoringLanguages(PatternRuleTest.j
ava:141)
at org.languagetool.rules.patterns.PatternRuleTest.main(PatternRuleTest.java:579)
Caused by: org.xml.sax.SAXParseException; lineNumber: 118; columnNumber: 26; The entity "Tab" was referenced, but not de
clared.
at com.sun.org.apache.xerces.internal.util.ErrorHandlerWrapper.createSAXParseException(Unknown Source)