@udomai, update 2020-10-23
I changed the rule to use the Unicode code point: Unicode Character 'CHARACTER TABULATION' (U+0009). Also, I used tokens rather than regexp. Unicode code points work fine in NON_STANDARD_ALPHABETIC_CHARACTERS.
<rule id="TAB_CHARACTER2" name="Find a tab character">
<pattern>
<token/>
<token regexp="yes">\b(\u0009|\u043E)\b</token>
<token/>
</pattern>
<message>Found a tab v2</message>
<short>Tab</short>
<example correction="">Cyrillic small <marker>letter о is</marker> found.</example>
<example correction="">Tab character between <marker>two words</marker>.</example>
<example>No tab character.</example>
</rule>
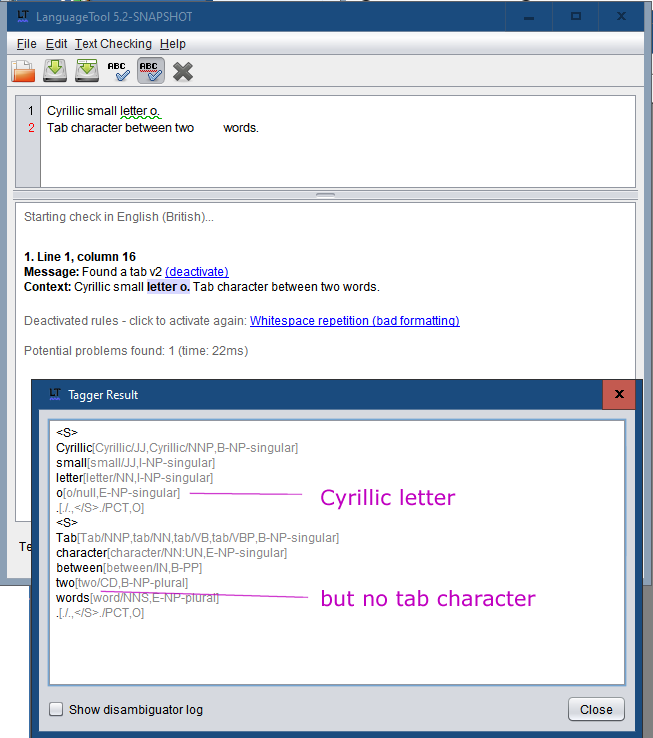
Testrules gives this warning:
Exception in thread “main” org.languagetool.rules.patterns.PatternRuleTest$PatternRuleTestFailure: Test failure for rule TAB_CHARACTER2[1] in file /org/languagetool/rules/en/grammar.xml: Tab character between twowords."
Errors expected: 1
Errors found : 0
Message: Found a tab v2
Note: twowords
LT does not ‘see’ the tab: