I proofread texts of old Ukrainian books which were OCRed and the orthographies of these books are often recognized as different language. Can the extension be forced to treat every text as Ukrainian? I really need to use it since the Ukrainian module allows to semi-automatically fix the words that contain mix of Latin and Cyrillic scripts
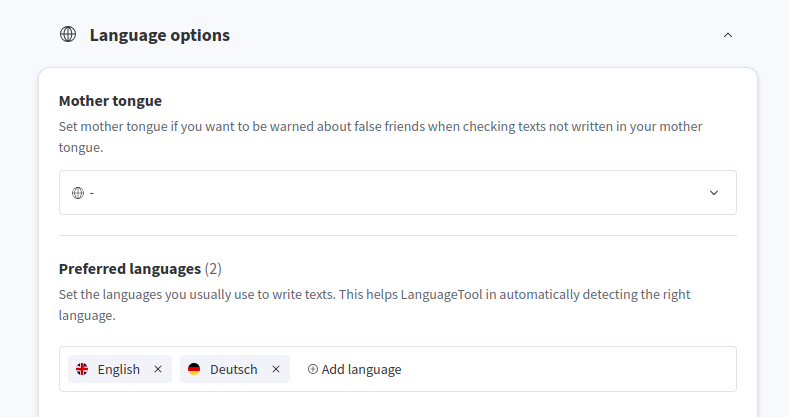
Sorry, that’s not possible. You can set Ukrainian as the only language in the setting under “Preferred languages”, to improve detection quality:
Which extension are you talking about? In the LibreOffice extension, go to Tools > LanguageTool Options > General, and switch from Use document language to Set language to, and select Ukrainian.
Thank you for the advice. Unfortunately, I need it for browser extension.
But why (and how) do you use a browser to proofread OCRd books?
I usually proofread books on Wikisource and in this case it is not a problem if a word contains mix of Cyrillic and Latin. Though, it is not desirable. Recently, they added Transkribus to their OCR models. And Transkribus allows you to train your own model, which then can be integrated into Wikisource. I proofread materials to create a Ukrainian model and would like it to not mix Cyrillic and Latin symbols. LanguageTool is quite effective to find such words.
Some of the books I proofread have quite obscure orthographies which are mistakenly recognized as either russian or Belorussian and I have to change language manually.
I would suggest a workflow as follows:
- Paste the text to LibreOffice (with LanguageTool installed as an extension).
- Apply the necessary language.
- Find / replace the most common cases such as c with с, i with і (you should use regular expressions for better precision and can create a macro for repetitive usage).
- Proofread and paste back.
Of course, it is a bit tedious, but one more advantage is that you can use your own dictionaries to accommodate unusual orthographies.