Hi all,
I am trying to add support for Sanskrit.
Following the instructions in the “Adding a new language” page, I have forked the LT repo, created the minimum required files/folders for Sanskrit and added the necessary config.
I have created a simple spellchecking dict using a small list of about 20 words, with the help of the steps given in the docs and in a discussion in the forum. Also I have added a few rules using the grammar.xml file.
After building (mvn clean package -DskipTests), I am getting support for Sanskrit in the standalone app.
So far so good. No errors (except for the tests failing due to some issue in the language-en module).
But when I tested the spellchecker with various words, I got weird results:
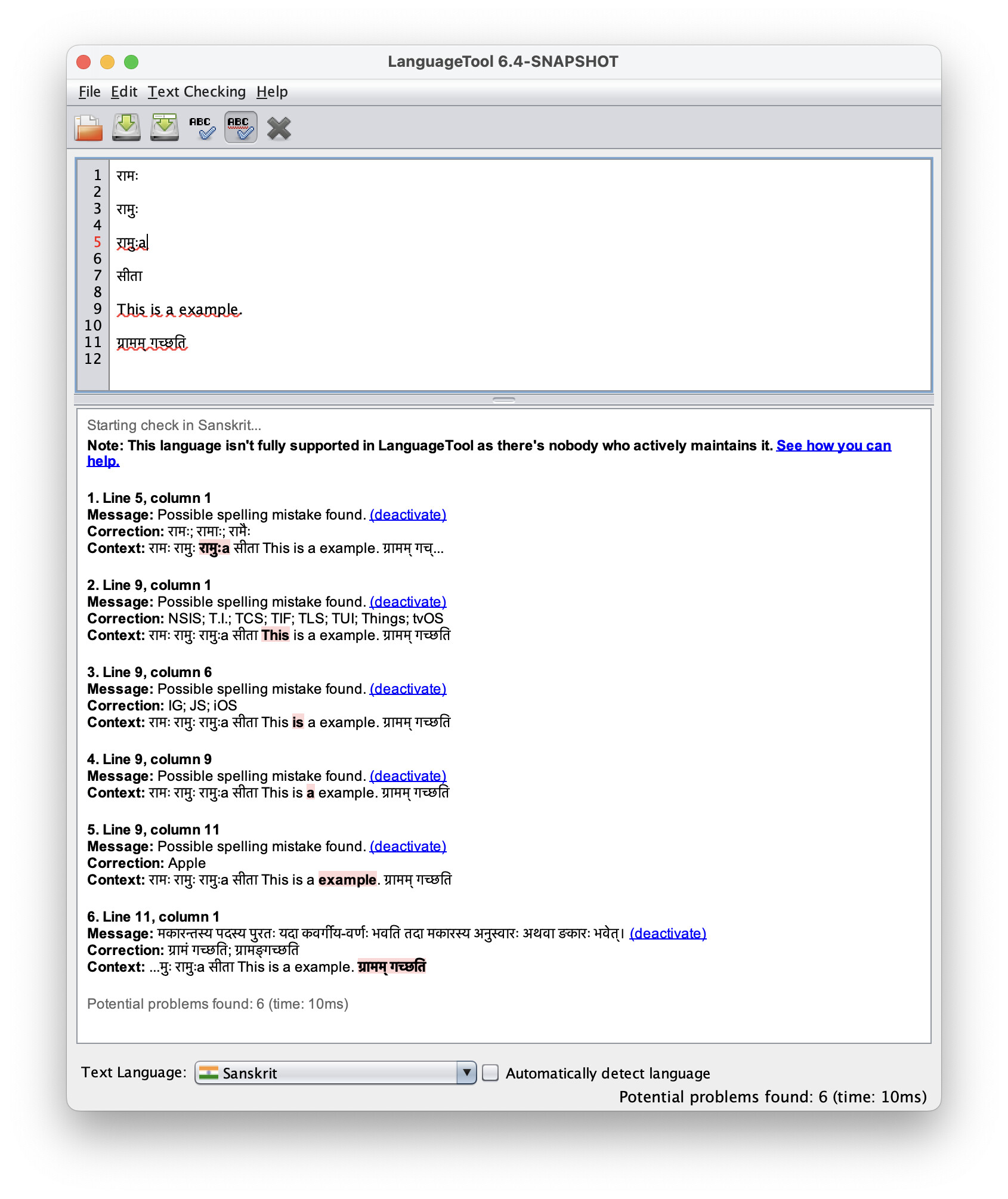
- रामः (line 1) is a valid word in the dict and it is getting recognised (I think).
- रामुः (line 3) is an invalid word and is not in the dict. But the spellchecker does not mark it and no suggestions are shown.
- But if a Latin word character is added to the invalid word (line 5), the word is correctly marked as invalid and suggestions are shown.
- सीता (line 7) is not in the dict. But the spellchecker doesn’t show any error.
- The word “example” (line 9) is getting the suggestion “Apple”. I don’t understand where the spellchecker is getting it from. Global dict?
- However, my grammar.xml rules are working as expected.
Are the issues in 2 & 3 due to some script problem? Do I have to configure the script for Sanskrit somewhere?
How to make the spellchecker always mark out-of-vocabulary words (issue in 4) as errors?
How to make the spellchecker not show suggestions for non-Sanskrit words (issue in 5)?
This is my fork, for your reference. Please let me know if I am doing something wrong.
Thanks in advance.
– Prasanna