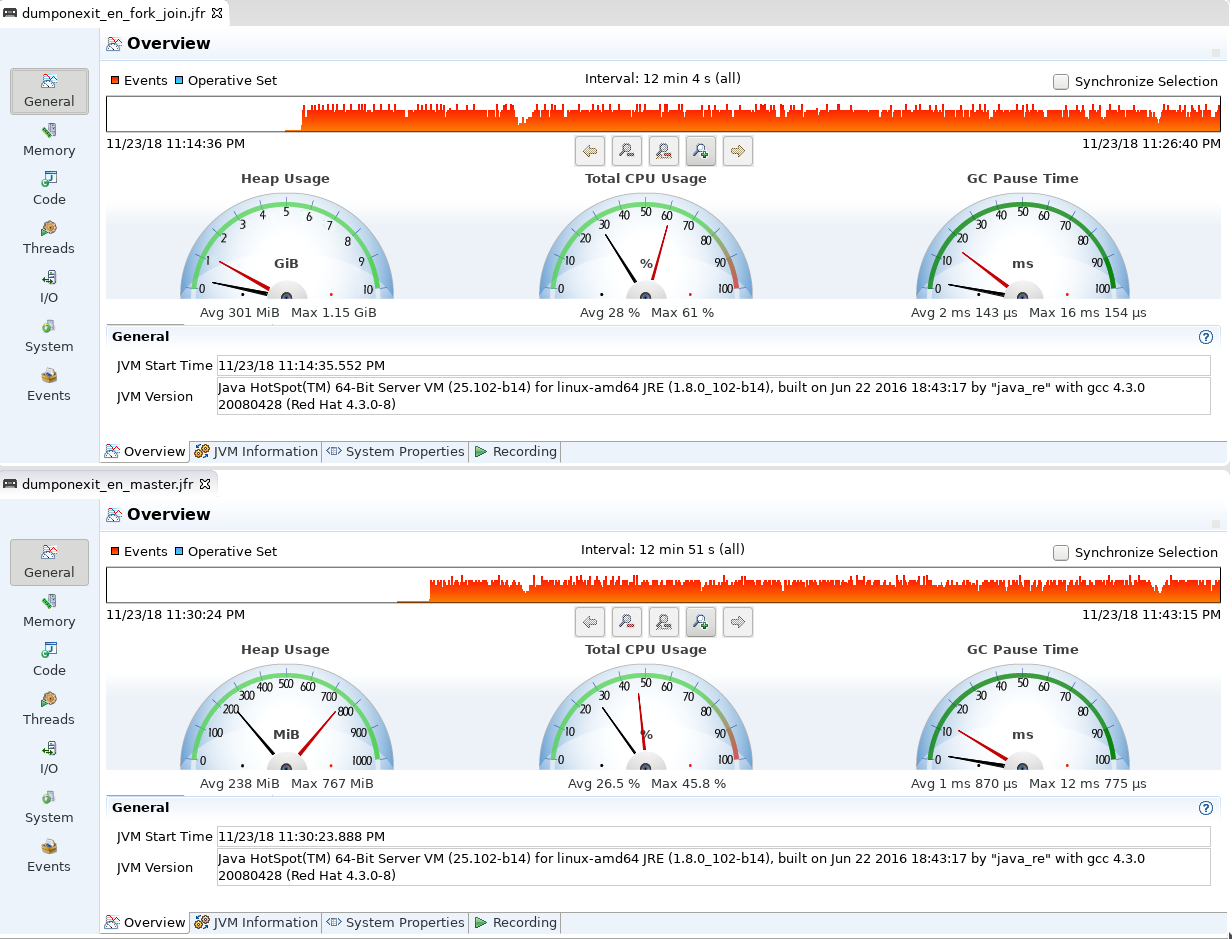
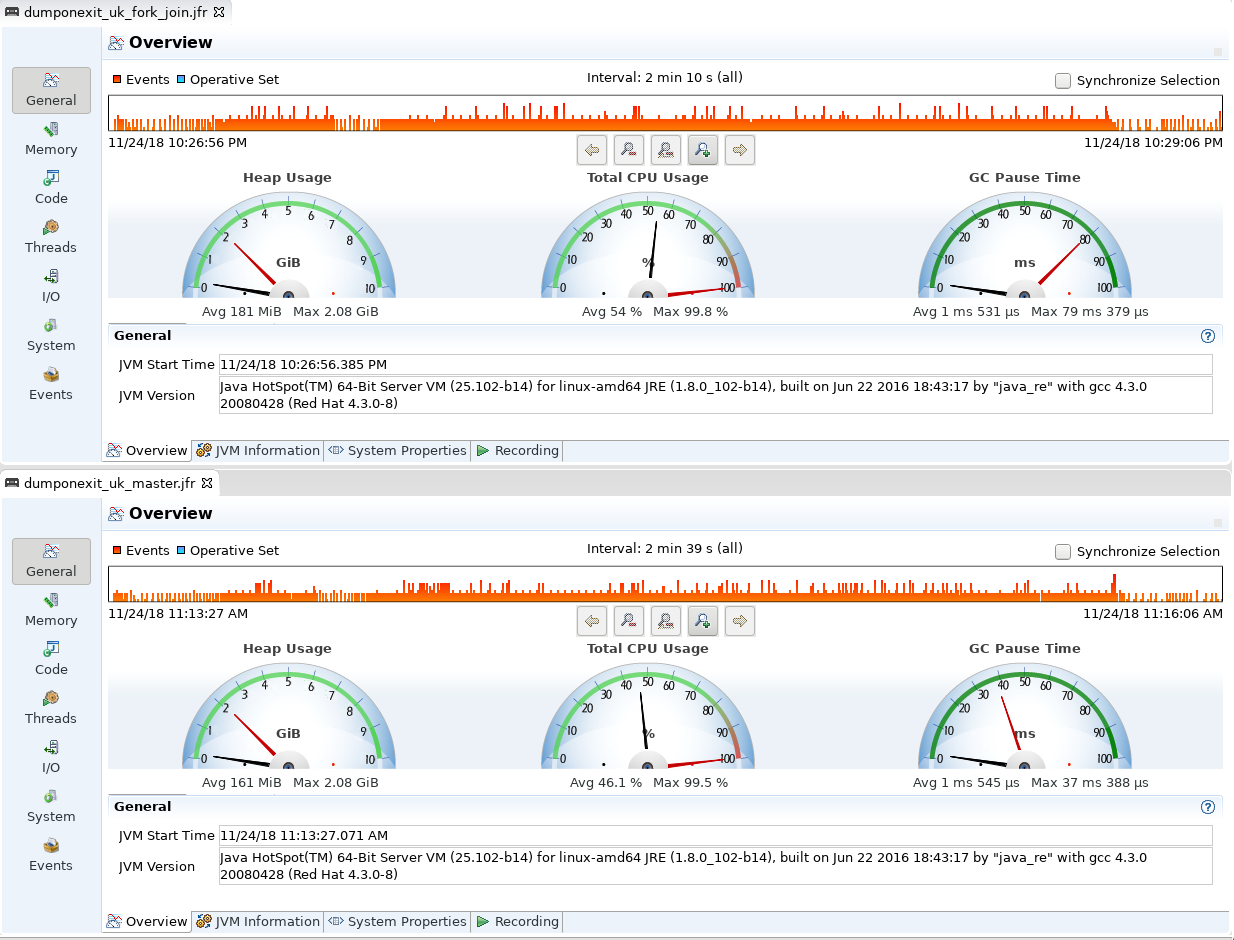
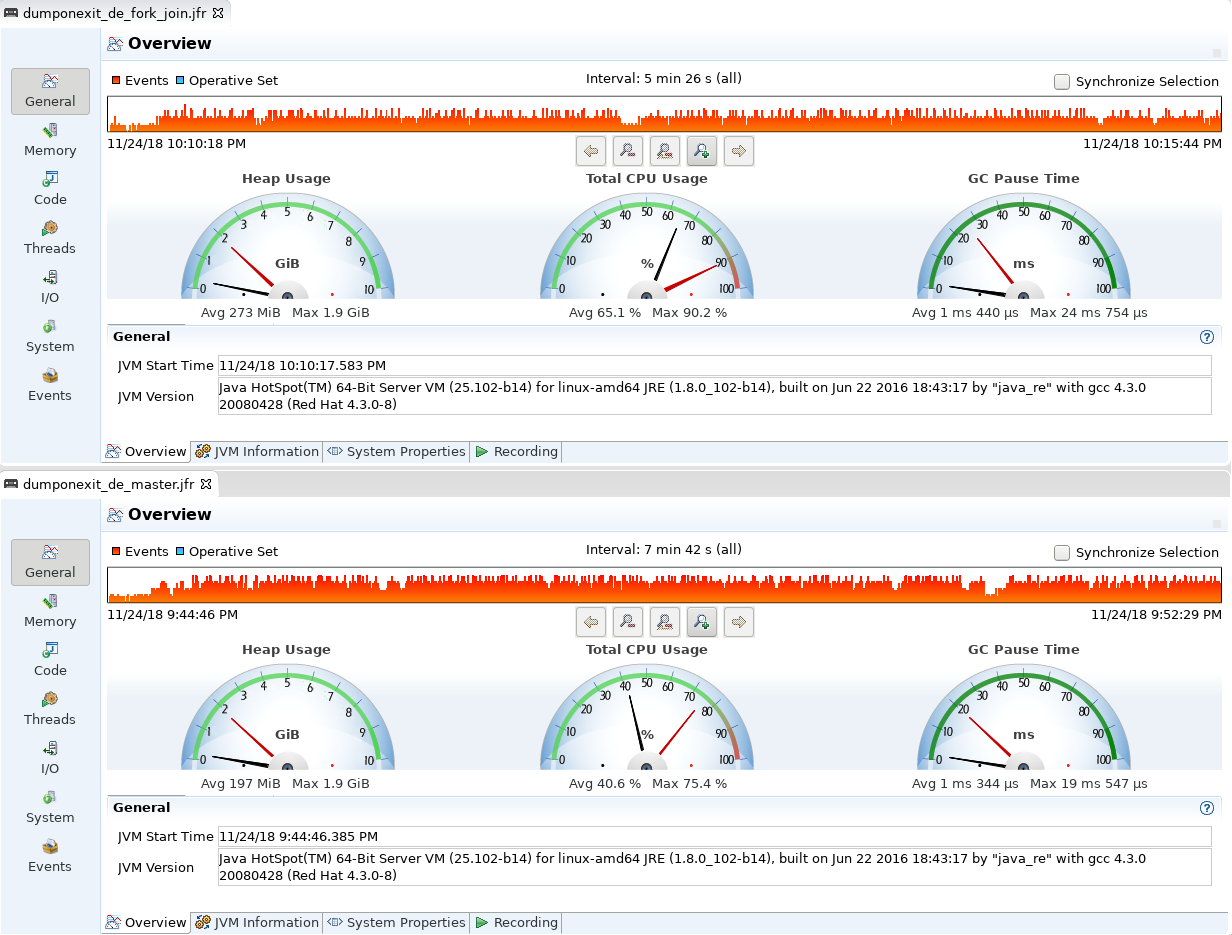
I’ve finally had some time to test more fork-join-pool approach again. I’ve made some tests (using ~1.4 million words for uk and en and ~943k words for German) and I’ve seen some performance improvements on fork-join-pool:
Ukrainian check (591 rules) was ~20% faster (I actually have seen almost 30% faster speed on bigger text)
German (2728 rules) was almost 30% faster
English (2147 rules) was ~6% faster
For en and de I’ve just merged some books from project Gutenberg.
My checks ran with org.languagetool.commandline.Main --line-by-line
So I’ve rebased forkjoinpool on master, made it work, and pushed it in (note: I had to force push as history in this branch was broken but nobody works on it so there was no reason to complicate history with merges).
As you can see from jmc screenshots CPU utilization went up accordingly.
This seems very good.
Is there any negative side to this? If not, I believe that everyone would be happy to see this integrated in the master repo. Are there any plans for it?
As multi-threading processing is affected by many factors (number of cores, type of the text, number and complexity of the rules etc) the main problem is making sure it does not decrease performance.
Last time I’ve tried this approach Daniel reported ~10% slowdown for (3 MB) German text so this time I’ve tried 3 languages.
But we probably want to test this more in other environments.
The main resource ogg I see on my side mostly RAM as the limiting factor.
This affects all languages with significant development and a large rule set. Spell checking using Hunspell, which Portuguese does, is extremely slow for each word that is not recognized. The remaining in comparison is very fast. If that process is already parallelized it is already a huge improvement. If in the situations where all words are recognized and the time of processing increases, it really does not matter, because it will still be fast, and the slower situation will be improved, shaving, at least, the total grammar processing time.
Spell-checking has been parallelized? If so, all languages with Hunspell will reap benefits.
And a suggestion: can you leave here a link to a build of the languagetool- (standalone tool if possible) in that fork. This will allow me and the other maintainers to easily test this change in their language and report to you the results.
Hunspell is not always fast making suggestions for compounded words. That can be tweaked by a parameter in the affix file for the number of suggestions to generate.
There is a follow-up of Hunspell in the making (Nuspell) which will be better at that, but is not at that level yet.
> # maximum number of compound suggestions
> # limit to 1 to prevent nonsense suggestions
> MAXCPDSUGS 1
>
> # max difference to be applied for all words (compounds and n-gram suggestions)
> ONLYMAXDIFF
>
> # max difference in chars for ngram suggestions
> # 3 limits wild suggestions a lot, but also drops suggestions for words with multiple errors
> MAXDIFF 3
Unfortunately these don’t help much with German (tested with German and hunspell 1.6.2 on the command line, tried several values for MAXDIFF and combinations of these parameters).
@arysin
Many thanks. Preliminary tests in Portuguese look quite good.
I ran a few newspaper articles on it and it reduced on average 30% total time, just like in other languages.
~900ms to 700ms
1.500ms to 1, 250ms
11s to ~10.2s in a texts full of unrecognized words.
Only oneproblem for now, probably due to using an old repo version. I noticed a change in underline color (green for style turned to blue) in the default text example with errors.
I will make a few systematic tests and report back later.
@tiagosantos Thanks Tiago, last time it was @dnaber who reported slowdown, so if Daniel confirms he does not see decreased performance anymore we can push it in.
I don’t recall what I tested last time. I think the use case I care about most is not affected (it’s the server, which doesn’t use multithreading in this sense).
@arysin I have been using your build this week, and although I have used it sparingly, I haven’t noticed anything unusual.
It is just faster and occupies less RAM. Portuguese and English ‘vanilla’ ~630MB, while your version ~570MB.
It would be great if you push it. We can check if there are any detection changes immediately in the daily regression test.
It seems good. But regression tests gave some odd results.
All languages tested had changes, mostly removing detection followed by a new detection of the same rule in another position of the diff.
Portuguese had some new error detections, and one Arabic portion that was being detected by phrase repetition disappeared. This portion should no even be in the Portuguese regressions. All this seems to be correct, but I do not understand what these changes actually mean.
I haven’t checked in detail, but remember that the output is really just the output of the Linux command diff, it is purely line-based. So it can happen that it gets confused and shows a rule that appears at a slightly different position as a deletion + insertion.
Regression is okay, but the perfomance graph shows quite a difference for Dutch. Which could be this change, but also the update of dictionaries and rules. But Dutch is not the only language with an increase st the end of the graph.
For all languages together, the graphs went up for some percents.