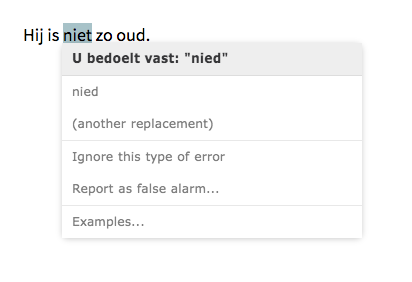
In dutch, when we type ‘niet’ which means ‘not’, we always get a correction and the word ‘nied’ as replacement which doesn’t exist in dutch (as far as I know). I think this is a typing error in the tool and probably should be ‘niet’. Could you check and correct this please? Constantly seeing the yellow line for a word that is correct is kind of annoying. Thank you!
Unfortunately I don’t know any Dutch, so I can’t judge if this is really a false alarm.
Good feedback. It is the result of a recently added rule, because ‘niet’ is not just a negation, but also a form of the verb ‘nieten’.
I added an exception for this, live tomorrow.
There might be more exceptions to be added. So please let the user give any feedback there is.
The test is not much more than running LT every day and making a diff of the output (today vs. yesterday). So you can just run the current languagetool-commandline.jar with the same input every day. To replicate the tests exactly, you’d need the same Wikipedia and tatoeba input, but that’s not that useful. Just use some input that doesn’t change.
It takes a lot of time to compile LT for full, process about 100.000 sentences, run the diff and check it.
I am sure it will improve quality, but will reduce the numbers of rules added as well.
Nevertheless, I will try to make a procedure. One that is also able to test just one rule. (disabled and enabled, and compare)
Did that; remove unnecessary output with grep; piped it through more. Gives a good idea of the ratio good/bad and insight in possible easy exceptions.
Tweaked the rule a bit doing that.
Applying all rules is just extremely slow.
I might make a routine that check grammar.xml for rules changed, and generate a list from that, for the test routine to use. Disadvantage of both solutions is that blocking overlap between rules is not detected.
Running test of indivual rules into individual result files now. Might take a lot of time.
In the meantime, dictionaries will be expanded. All words present on at least 10 sources are being reviewed and automatically flexed.