I have created in 3-tab separated format. Dictionary built successfully. But, I cannot use the dictionary. I am getting no replacement when I am using the newly built dictionary.
Thank you for your response Yakov. But I am not trying to modify the spell checker dictionary. I am trying to modify the synthesizer dictionary. Please let me know if you have any options regarding this.
For synthesizer dictionary need extract POStag dictionary english.dict from /languagetool-language-modules/en/src/main/resources/org/languagetool/resource/en
This method works fine. Thank you.
I have seen that there is also an option to export spell checker dictionary.
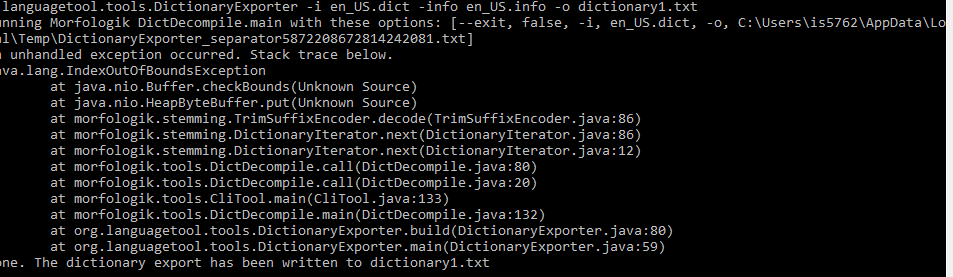
But, I am facing while trying to export en_US.dict.
I guess, you can help me in this too.
For spellchecker dictionary with frequency data is impossible export word list due bug.
English spellcheck dictionaries contain frequency data.
But you can get word list from source hunspell dictionary using hunspell utillity unmunch.
@Yakov: There are bugs in unmuch, i.e. it does not support the full feature set of Hunspell, only the affix part of it. So it can result in words that are actually wrong.
The step needed to assure this is not the case is spellcheck the resulting file using Hunspell and remove the words reported by -L (wrong) , e.g.:
unmunch en_AU.dic en_AU.aff > en_AU1.txt
hunspell -d en_AU -L en_AU1.txt > wrong.txt
while read line; do cat en_AU1.txt | grep -a -v "^$line$" > tmp.txt; mv tmp.txt en_AU1.txt ; done < wrong.txt