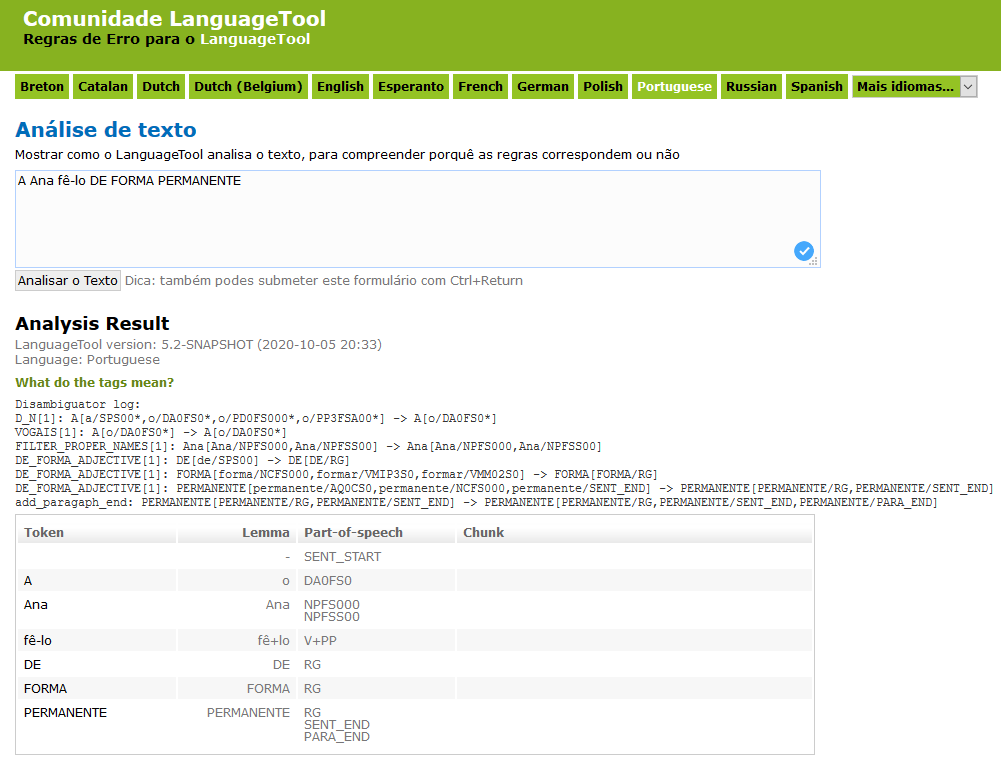
I am about to implement (tomorrow) a rule that replaces three words with an adverb:
“A Ana fê-lo DE FORMA PERMANENTE” → “A Ana fê-lo PERMANENTEMENTE”
But I will need to make many changes in added.txt.
I have been trying to find the POS for adverbs, but the morphologic dictionary says for the two words I typed there:
violentamente → RM
sintaticamente → RG
What is the difference between RM and RG? Is one of them incorrect?
Here is how the rule looks like in draft (any suggestions are welcome):
<!-- DE FORMA/MODO + ADJ adv -->
<!-- Created by Marco A.G.Pinto, Portuguese rule 2020-10-07 (2-JUL-2020+) -->
<rule id='DE_FORMA-MODO_ADJ' name="De + forma/modo + Adj -> Advérbio">
<pattern>
<token regexp="no">de</token>
<token regexp="yes">forma|modo</token>
<token postag='AQ0[CFM]S0' postag_regexp='yes'/>
</pattern>
<message>Substitua por <suggestion><match no='3' postag='AQ0[CFM]S0' postag_regexp="yes" postag_replace='RM'/></suggestion>.</message>
<example correction="permanentemente">A Ana foi banida <marker>de forma permanente</marker> por violar as regras.</example>
<example type='correct'>A Ana foi banida <marker>permanentemente</marker> por violar as regras.</example>
</rule>
During sleep, I have been thinking… maybe we could use a Java file for it?
With the structure:
possível=possivelmente
atual=atualmente
… etc.
?
Then just check if the last word in the rule above is in that list.
I am also planning to use a similar rule to:
“delimitado com/por fronteiras físicas” → “delimitado fisicamente” (físicas → fisicamente)
not sure how to implement it too since the above Java file wouldn’t work.
The RM tags come from the Portuguese tagger, not the dictionary. “Violentamente” is not in the tagger dictionary, but the tagger detects that it is a feminine adjective + mente, and adds the tag RM.
You can synthesize this adverbs doing the same: synthesize the feminine adjective and add the string ‘mente’. <suggestion><match no='3' postag='AQ0[CFM]S0' postag_regexp='yes' postag_replace='postag='AQ0[CF]S0'/>mente</suggestion>
I don’t know if there can be any change in the word (diacritics) when “mente” is added. If that is the case, then it becomes more complex.
Then, somehow we could compare the current word with the left of each entry there (left of comma) and replace with the entry on the right of the comma.
Is it a good approach?
Theoretically this seems the best doable since it is easier to maintain a list of words with accent only.
It would be better to use a filter or to tweak a bit the synthesizer, and forget about maintaining lists of words. For example, use “RM” to generate in the synthesizer an adverb ending in -mente from an adjective (removing the diacritics).
But before doing anything, are you sure this is a good style recommendation? I wouldn’t do it in Catalan or Spanish, which have the same patterns. I would do this recommendation only if the pattern is used repeatedly in a text. What do you think, @udomai?
You can use this suggestion when the token doesn’t contain diacritics (check it in the pattern with an exception): <suggestion><match no='3' postag='AQ0[CFM]S0' postag_regexp='yes' postag_replace='postag='AQ0[CF]S0'/>mente</suggestion>
In the case there is a diacritic, I will adjust the synthesizer to do it.
<!-- DE FORMA/MODO + ADJ adv -->
<!-- Created by Marco A.G.Pinto, Portuguese rule 2020-10-08 (2-JUL-2020+) -->
<rule id='DE_FORMA-MODO_ADJ' name="De + forma/modo + Adj -> Advérbio">
<pattern>
<token regexp="no">de</token>
<token regexp="yes">forma|modo</token>
<token postag='AQ0[CFM]S0' postag_regexp='yes'/>
</pattern>
<message>Substitua por <suggestion><match no='3' postag='AQ0[CFM]S0' postag_regexp='yes' postag_replace='postag='AQ0[CF]S0'/>mente</suggestion>.</message>
<example correction="permanentemente">A Ana foi banida <marker>de forma permanente</marker> por violar as regras.</example>
<example type='correct'>A Ana foi banida <marker>permanentemente</marker> por violar as regras.</example>
</rule>
Exception in thread “main” java.io.IOException: Cannot load or parse ‘/org/languagetool/rules/pt/grammar.xml’
at org.languagetool.XMLValidator.validateWithXmlSchema(XMLValidator.java:109)
at org.languagetool.rules.patterns.PatternRuleTest.validatePatternFile(PatternRuleTest.java:200)
at org.languagetool.rules.patterns.PatternRuleTest.validatePatternFile(PatternRuleTest.java:176)
at org.languagetool.rules.patterns.PatternRuleTest.runTestForLanguage(PatternRuleTest.java:157)
at org.languagetool.rules.patterns.PatternRuleTest.runGrammarRulesFromXmlTestIgnoringLanguages(PatternRuleTest.java:152)
at org.languagetool.rules.patterns.PatternRuleTest.main(PatternRuleTest.java:683)
Caused by: org.xml.sax.SAXParseException; lineNumber: 7858; columnNumber: 120; Element type “match” must be followed by either attribute specifications, “>” or “/>”.
at com.sun.org.apache.xerces.internal.util.ErrorHandlerWrapper.createSAXParseException(Unknown Source)
at com.sun.org.apache.xerces.internal.util.ErrorHandlerWrapper.fatalError(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLErrorReporter.reportError(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLErrorReporter.reportError(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLScanner.reportFatalError(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.seekCloseOfStartTag(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLNSDocumentScannerImpl.scanStartElement(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl$FragmentContentDriver.next(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentScannerImpl.next(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLNSDocumentScannerImpl.next(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.scanDocument(Unknown Source)
at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(Unknown Source)
at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(Unknown Source)
at com.sun.org.apache.xerces.internal.jaxp.validation.StreamValidatorHelper.validate(Unknown Source)
at com.sun.org.apache.xerces.internal.jaxp.validation.ValidatorImpl.validate(Unknown Source)
at javax.xml.validation.Validator.validate(Unknown Source)
at org.languagetool.XMLValidator.validateInternal(XMLValidator.java:204)
at org.languagetool.XMLValidator.validateWithXmlSchema(XMLValidator.java:107)
… 5 more
Running disambiguator rule tests…
Running disambiguation tests for Portuguese…
Exception in thread “main” java.lang.RuntimeException: Could not activate rules
at org.languagetool.JLanguageTool.(JLanguageTool.java:334)
at org.languagetool.JLanguageTool.(JLanguageTool.java:293)
at org.languagetool.JLanguageTool.(JLanguageTool.java:353)
at org.languagetool.JLanguageTool.(JLanguageTool.java:260)
at org.languagetool.tagging.disambiguation.rules.DisambiguationRuleTest.testDisambiguationRulesFromXML(DisambiguationRuleTest.java:70)
at org.languagetool.tagging.disambiguation.rules.DisambiguationRuleTest.main(DisambiguationRuleTest.java:234)
Caused by: java.io.IOException: Cannot load or parse input stream of ‘/org/languagetool/rules/pt/grammar.xml’
at org.languagetool.rules.patterns.PatternRuleLoader.getRules(PatternRuleLoader.java:76)
at org.languagetool.Language.getPatternRules(Language.java:598)
at org.languagetool.JLanguageTool.activateDefaultPatternRules(JLanguageTool.java:634)
at org.languagetool.JLanguageTool.(JLanguageTool.java:327)
… 5 more
Caused by: org.xml.sax.SAXParseException; lineNumber: 7858; columnNumber: 120; Element type “match” must be followed by either attribute specifications, “>” or “/>”.
at com.sun.org.apache.xerces.internal.util.ErrorHandlerWrapper.createSAXParseException(Unknown Source)
at com.sun.org.apache.xerces.internal.util.ErrorHandlerWrapper.fatalError(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLErrorReporter.reportError(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLErrorReporter.reportError(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLScanner.reportFatalError(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.seekCloseOfStartTag(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.scanStartElement(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl$FragmentContentDriver.next(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentScannerImpl.next(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.scanDocument(Unknown Source)
at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(Unknown Source)
at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(Unknown Source)
at com.sun.org.apache.xerces.internal.parsers.XMLParser.parse(Unknown Source)
at com.sun.org.apache.xerces.internal.parsers.AbstractSAXParser.parse(Unknown Source)
at com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl$JAXPSAXParser.parse(Unknown Source)
at com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl.parse(Unknown Source)
at javax.xml.parsers.SAXParser.parse(Unknown Source)
at org.languagetool.rules.patterns.PatternRuleLoader.getRules(PatternRuleLoader.java:73)
… 8 more
It still throws many errors, but less than before:
<!-- DE FORMA/MODO + ADJ adv -->
<!-- Created by Marco A.G.Pinto, Portuguese rule 2020-10-08 (2-JUL-2020+) -->
<rule id='DE_FORMA-MODO_ADJ' name="De + forma/modo + Adj -> Advérbio">
<pattern>
<token regexp="no">de</token>
<token regexp="yes">forma|modo</token>
<token postag='AQ0[CFM]S0' postag_regexp='yes'/>
</pattern>
<suggestion><match no='3' postag='AQ0[CFM]S0' postag_regexp='yes' postag_replace='AQ0[CF]S0'/>mente</suggestion>
<example correction="permanentemente">A Ana foi banida <marker>de forma permanente</marker> por violar as regras.</example>
<example type='correct'>A Ana foi banida <marker>permanentemente</marker> por violar as regras.</example>
</rule>
Running XML validation for pt/grammar.xml…
cvc-complex-type.2.4.a: Invalid content was found starting with element ‘suggestion’. One of ‘{filter, message}’ is expected. Problem found at line 7859, column 19.
Exception in thread “main” java.io.IOException: Cannot load or parse ‘/org/languagetool/rules/pt/grammar.xml’
at org.languagetool.XMLValidator.validateWithXmlSchema(XMLValidator.java:109)
at org.languagetool.rules.patterns.PatternRuleTest.validatePatternFile(PatternRuleTest.java:200)
at org.languagetool.rules.patterns.PatternRuleTest.validatePatternFile(PatternRuleTest.java:176)
at org.languagetool.rules.patterns.PatternRuleTest.runTestForLanguage(PatternRuleTest.java:157)
at org.languagetool.rules.patterns.PatternRuleTest.runGrammarRulesFromXmlTestIgnoringLanguages(PatternRuleTest.java:152)
at org.languagetool.rules.patterns.PatternRuleTest.main(PatternRuleTest.java:683)
Caused by: org.xml.sax.SAXParseException; lineNumber: 7859; columnNumber: 19; cvc-complex-type.2.4.a: Invalid content was found starting with element ‘suggestion’. One of ‘{filter, message}’ is expected.
at com.sun.org.apache.xerces.internal.util.ErrorHandlerWrapper.createSAXParseException(Unknown Source)
at com.sun.org.apache.xerces.internal.util.ErrorHandlerWrapper.error(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLErrorReporter.reportError(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLErrorReporter.reportError(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLErrorReporter.reportError(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.xs.XMLSchemaValidator$XSIErrorReporter.reportError(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.xs.XMLSchemaValidator.reportSchemaError(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.xs.XMLSchemaValidator.handleStartElement(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.xs.XMLSchemaValidator.startElement(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.dtd.XMLDTDValidator.startElement(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLNSDocumentScannerImpl.scanStartElement(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl$FragmentContentDriver.next(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentScannerImpl.next(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLNSDocumentScannerImpl.next(Unknown Source)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.scanDocument(Unknown Source)
at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(Unknown Source)
at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(Unknown Source)
at com.sun.org.apache.xerces.internal.jaxp.validation.StreamValidatorHelper.validate(Unknown Source)
at com.sun.org.apache.xerces.internal.jaxp.validation.ValidatorImpl.validate(Unknown Source)
at javax.xml.validation.Validator.validate(Unknown Source)
at org.languagetool.XMLValidator.validateInternal(XMLValidator.java:204)
at org.languagetool.XMLValidator.validateWithXmlSchema(XMLValidator.java:107)
… 5 more