In Microsoft Word, use ‘smart quotes’. Type some text and include quote marks.
Save as a text file and use the default save options.
Open the text file in a text editor. (You cannot see the quote marks.)
Copy the text to LT. (The quote marks are in the pasted text.)
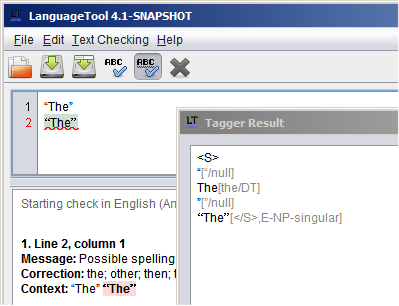
LT gives a warning for spelling.
In the LT screen shot, line 1 contains pasted text from the Word document. Line 2 is pasted text from the text document:
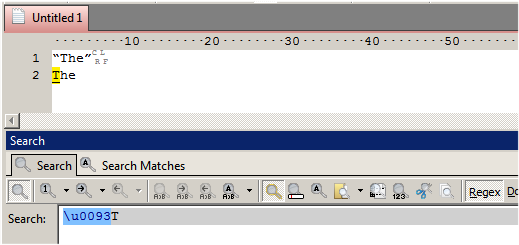
I copied the 2 lines from LT into a text editor. The screen shot from the text editor shows that in line 2, character u0093 comes before the T. (u0092, u0093, u0094 are control characters: O'Reilly Media - Technology and Business Training).
Should LT tokenize on u0092, u0093, u0094?
If no, is it possible to change the spelling checker such that it does not give a spelling error for correctly spelled words that are in the quote marks?
If it is possible, should we do it? (What possible problems are there if the behaviour is changed?)
If we should do it, can one of the Java developers please do it?
Could you provide such a file here (zipped)? According to Unicode Character 'PRIVATE USE TWO' (U+0092), this looks like a quote, but actually seems to be some kind of reserved character.
I wrote, “You cannot see the quote marks.” The cause of that was because the default text encoding in the editor is UTF-8. When I change the encoding to Windows 1252: Western European, I can see the quote marks.
This screen shot from Word shows the result from a macro that gives the ANSI value of the text that I typed into Word.
Although the characters are reserved (as shown in the oreilly link, which shows the equivalence between the ANSI values and unicode), Word/Windows uses them for curly quotes.
In the text editor, if the text is encoded as UTF-8, and I copy it to LT, I get the spelling error. If I convert the text to Windows 1252 and then paste into LT, there is no spelling error.
If I copy the text that gives a spelling error in LT back into Word, I get this:
which is not what I started with.
In LT, the characters are u0093 and u0094. I know because I have grammar rules that find them. Example:<token regexp="yes">.*(\u0093).*</token>