Normally, in Dutch, after space-full stop there is a sentence end when followed by a capital.
Except for .Net, .NET
Trying to get this exception in srx failed.
I cannot even find where the general sentence end is programmed in the srx.
Can anyone succeed in making an exception like this?
I thought this would do the trick, but it did not:
<rule break="no">
<!-- .Net -->
<beforebreak>\s[.]</beforebreak>
<afterbreak>[Nn][Ee][Tt]( |-)</afterbreak>
</rule>
Not only .NET, but also domain names or file extensions: .com, .JPG. There is no sentence split in Dutch, similarly to most languages.
There is a false positive in the rule COMMA_PARENTHESIS_WHITESPACE, but that is not related to sentence splitting.
2.) Line 1, column 4, Rule ID: COMMA_PARENTHESIS_WHITESPACE
Message: Zet geen spatie voor een punt
Suggestion: .
het .NET-platform
^^
That is not the issue.
.net is okay, so is .NET, even .NEt.
But .Net causes a sentence split.
Net is also a normal, capitalized word, so ther is a big chance of falses either way, but the number of correct words after .Net is limited, so falses can be reduced.
Sorry. You are right.
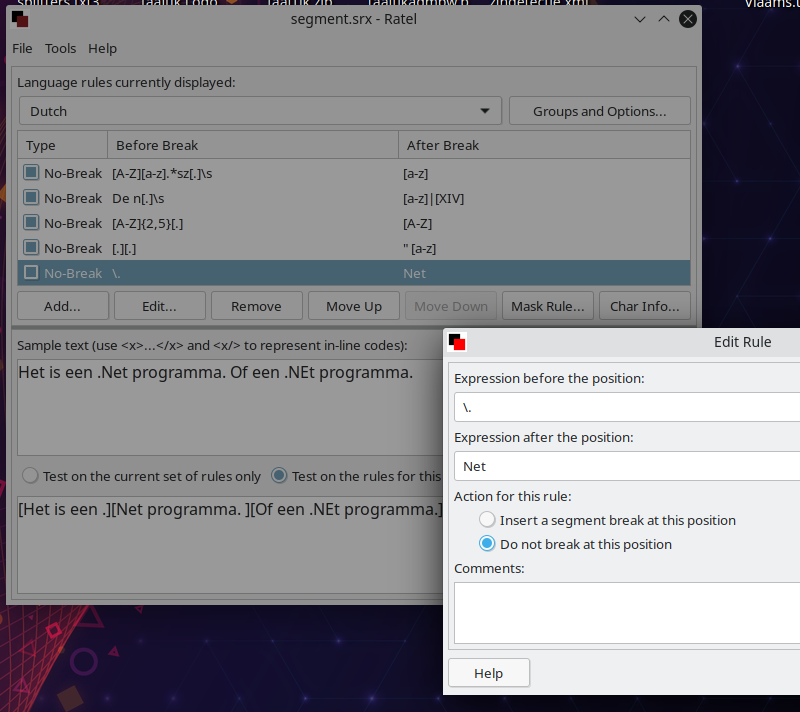
But your SRX rule (or this rule below) works for me as expected:
<rule break="no">
<beforebreak>\.</beforebreak>
<afterbreak>Net</afterbreak>
</rule>
There is only one SRX file.
The position of the rule inside the file has an effect. With the rule at the start of the Dutch rules, it works, but not if it is at the end.
I tried that too. No success. I give up.
Thanks. I will have get it from GIT and adjust it, because it should also catch Net-.* ( for the rare cases it is used correctly in a compound, like .Net-architectuur.