We’ve successfully released a major update of our browser add-on for Chrome a few weeks ago. We’re now working on releasing the same add-on for Firefox, but we need your help to test it!
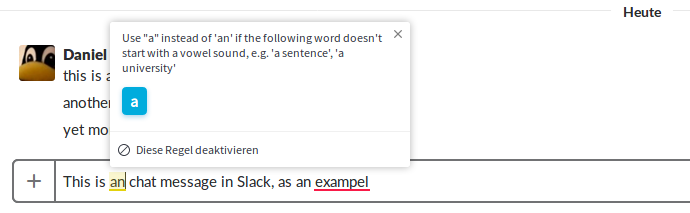
The new add-on works almost anywhere on the web and it will underline potential issues like this (using Slack as an example):
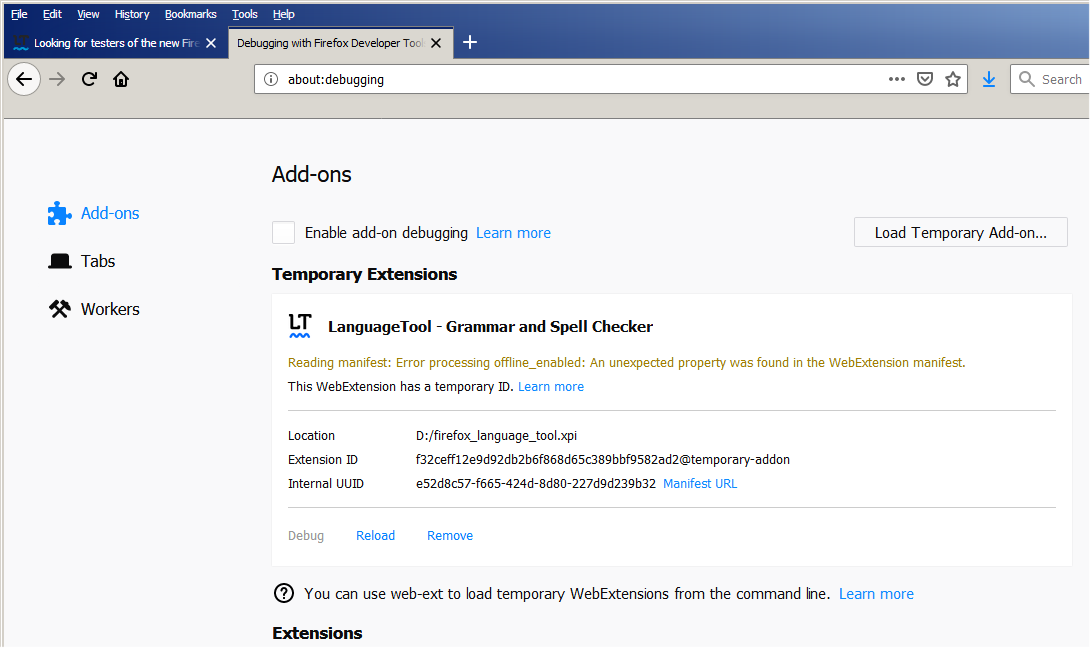
If you’re a Firefox user, please help us test the add-on and let us know your feedback here. Here’s how to install the new add-on:
Deactivate or uninstall the existing LanguageTool add-on first, if you’re using it (you don’t have to do this, but it’s recommended)
Enter about:debugging in the browser’s address bar
Click “Load temporary add-on…”
Select the downloaded file
Confirm the privacy dialog and the add-on should be ready for use
Note that directly after installation, it might be required to reload a tab on which you want the add-on to work
Please note: Due to a limitation in Firefox, the add-on will be gone when you restart Firefox. This is due to the development mode, the final add-on will not have that issue.
Did you use the “Load temporary add-on…” button? I noticed that dragging the *.xpi onto the Firefox window gives me the “corrupt” message, too. But selecting the file in the file dialog works.
Ahh, my bad, was too excited so didn’t read carefully
Works pretty good, although for some short Ukrainian texts it checks it as Russian even though the web-page has <html lang=“uk” and my browser has Ukrainian language in preferences.
I’ll keep testing and will report if I find anything else.
I’ve tested it on several sites and it looks pretty good.
Several notes:
once it started checking and never stopped (at least after ~2 min), I suspect maybe connection was lost? not a biggie, page refresh takes care of it, not sure if it’s easy to implement some timeout
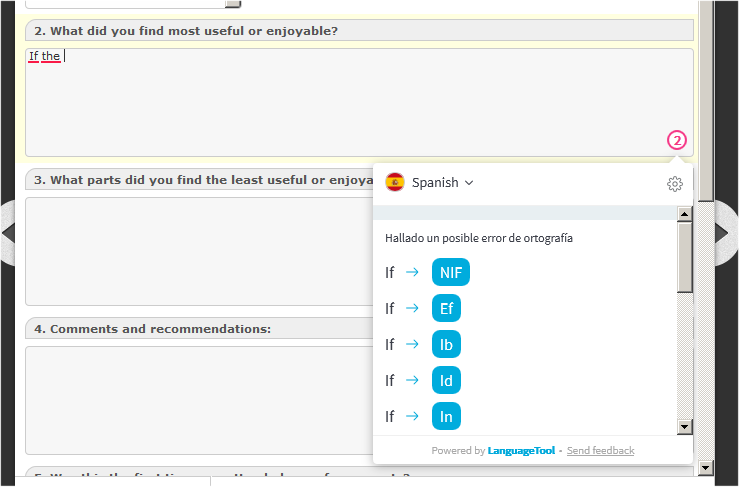
language detection on short sentences is flimsy, e.g. as I mentioned Ukrainian text often considered Russian, also I think IPA may trigger treating English as other languages (e.g. “downloadd [ˌdaʊnˈləʊd, ˈdaʊnloʊd]” will check with Russian similar phrases with German etc); I wonder if it’s possible with auto-detect to indicate which language was chosen (before I click)
I noticed no-break space (U+00A0) gets removed when checking, so the check thinks there’s no space (this one I found on Wikipedia page, e.g. see “1905 р.”)
I second that. Nu fuss, no tech details, just functionality. Nevertheless, a question: are the personal dictionaries language aware? i.e. words stored for the detected language only?
(And there is a false positive in this text… I guess.)
In OpenOffice I use two sets of personal dictionaries, a global set for names and a per-language set for, among other things, rare permutations of words, in-universe legalese (EG: explicify: to make an implicit fact of law, explicit, primarily used in the past tense to differentiate from mere codification) and (perhaps in-universe) slang.
So I think it may help to have at least the option to add a word locally instead of globally.
e.g. sentence “Зараз десь когось нема” has 3 Ukrainian words that are not present in Russian and 4th one that is only used in poetry etc, it’s detected as Russian.
I wonder if that’s what fasttext library we’re using returning, so I may need to open issue at their github
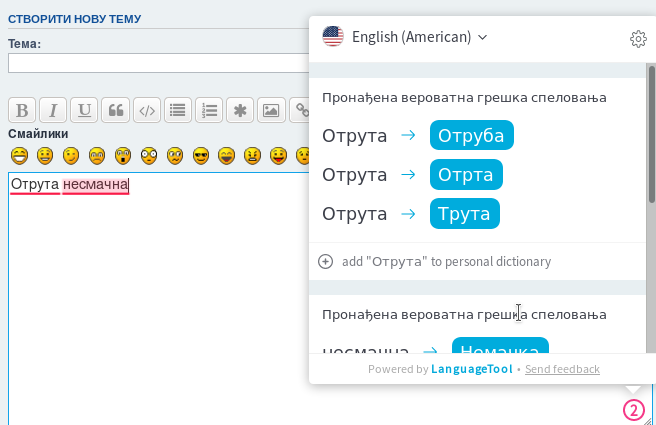
Another interesting example: I entered 2 Ukrainian words and when I click on “2 errors” indicator it says English (American) but fix suggestions are from Serbian(?)
Yes, it’s a fasttext issue. I wonder whether they will consider this an error, as their approach is 100% machine learning and short texts are known to be difficult. But it’s worth a try.
Serbian is detected but it’s not in the drop-down… I’ve added that to my personal to do list.
Another thing I noticed is it starts checking very quickly, I type pretty fast and I can see the wave begins while I am still typing my first word (which is too early for language detection anyway). I wonder if it makes sense to either wait for user to pause, detect spaces/punctuation, or just make a check delay a bit longer.