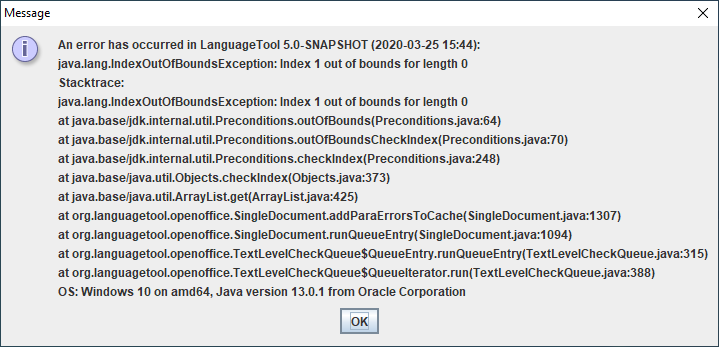
Hm, ich weiß nicht, ob es hierher gehört oder nicht.
Der Fehler kam beim bearbeiten eines anderen Dokument. Es wurde nur formatiert von Standart auf Titel.
Ich vermute, dass das große Dokument noch im RAM war, wodurch es zu dieser Fehlermeldung kam.
Hm, ich weiß nicht, ob es hierher gehört oder nicht.
Der Fehler kam beim bearbeiten eines anderen Dokument. Es wurde nur formatiert von Standart auf Titel.
Ich vermute, dass das große Dokument noch im RAM war, wodurch es zu dieser Fehlermeldung kam.
Hier nochmal eine neue Version. Wäre toll, wenn du die testen könntest: https://we.tl/t-Ua8xzTB6E8
Das mache ich jetzt.
Zunächst die Version funktioniert.
Sie ist nur sehr langsam unterwegs und scant nicht markierte Texte, sondern gleich das ganze Kapitel.
Das ist immer noch kontraproduktiv, denn dadurch dauert das Ananlysieren ewig. 10 min. Um ein Ergebnis zu kriegen, was man gar nicht möchte. Schließlich wollte ich nur einen markierten Bereich analysieren.
Das funktioniert wiederum in LT 4,8.
Zudem ist der Fehlalarm weiterhin vorhanden, dass alle nicht Nomen und Eigenwörter nach einer wörtlichen Rede als Fehler markiert werden.
Z. B.: Saskia sagte fröhlich: „Ich hätte nicht gedacht, euch hier anzutreffen.“ Die Umarmung wurde gelöst und Anastasia sagte: „Ich hätte auch nicht gedacht, dass wir dich hier antreffen.“
LT beschwert sich bei “Die”, dass nur Nomen und Eigennamen großgeschrieben werden. Dabei vergiss es, dass es ein Satzanfang ist und die werden immer großgeschrieben.
Zum RAM-Verbrauch ist die LT-Version sehr zurückhalten mit 1,5 GB. Das ist wirklich positiv, denn ältere Versionen hatten gernen einen Verbrauch von 2 bis 3 GB.
Trotzdem muss ich leider sagen, dass diese Version nicht produktiv genutzt werden kann.
Zu der langsamen Analyse kann ich sagen, dass dies nur bei großen Dokumenten der Fall ist. Z. B. mein Roman, der in Kapiteln gespalten ist. Ein kleines Dokument wird sofort analysiert, aber auch hier wird einfach alles analysiert und nicht der markierte Bereich.
Danke fürs Testen!
@Fred.Kruse Dieser Fehler scheint also noch nicht behoben.
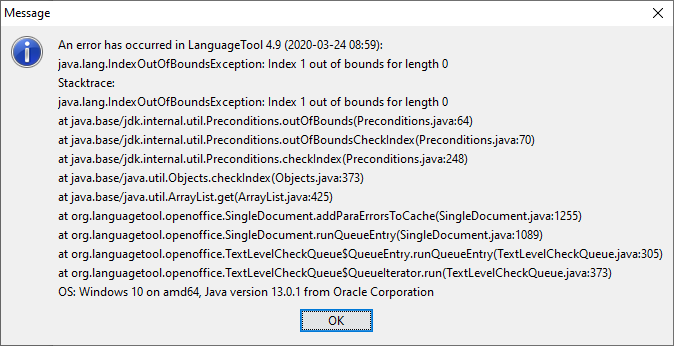
Wichtig!, der obengenannte Fehler sollte nicht ingnoriert werden, er kann LibreOffice zum Crashen bringen. Das ist mir gerade nämlich passiert. Gar nicht schön.
Erst kam der Fehler und wenig später ist das Programm ohne Vorwanung abgestürzt.
Zum Glück nur kleiner Datenverlust.
Hattest du gerade vorher ein Dokument geschlossen?
Das mit dem Scannen habe ich nicht ganz verstanden. LT analysiert immer den ganzen Text eines Dokuments und markiert die potenziellen Fehler. Wenn du einen Bereich markierst und mit “Text prüfen” den Dialog aufrufst, werden im Dialog nur die Fehler der Reihe nach durchgegangen, die im markierten Bereich auftreten. Das sollte in beiden Versionen gleich sein.
Ich habe kein neues Dokument geöffnet oder altes geschlossen.
Das LanguageTool scannt normal das ganze Dokument und hat Fehler gefunden.
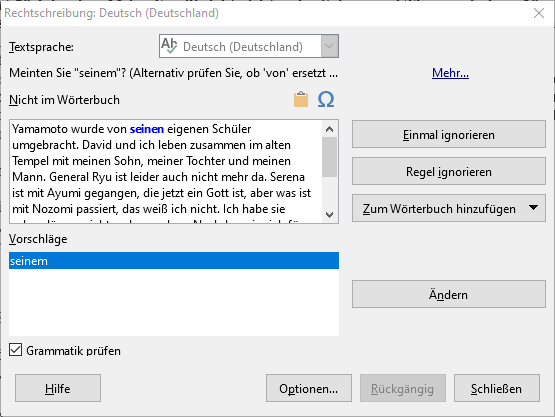
Das ist die Ausgabe der Prüfung und hier liegt der Fehler. Das ist nicht der markierte Text, den ich markiert habe. Das hat bis Version 4,8 immer funktioniert.
Das LanguageTool ignoriert bewusst die Markierung des Nutzers und scannt in der gesonderten Rechtschreibprüfung alles aus einem Kapitel. Dies kann bei einem Roman von 10 min bis Stunden dauern, da man jeden Fehler erstmal ignorieren muss, bis man zum gewünschten Fehler angekommen ist.
Ich hoffe, dass du jetzt das Problem verstehst.
Hier nochmal ein Update: https://we.tl/t-io94ZA7wt5 - das mit dem markierten Text ist noch nicht behoben (oder, @Fred.Kruse?), aber der Absturz mit der IndexOutOfBoundsException, zumindest wenn man die Default-Einstellungen hat, sollte nicht mehr auftreten.
Die Funktionsweise des Dialogs wird nicht von LanguageTool gesteuert, sondern von LibreOffice (LT führt nur den Check für den Dialog Satz für Satz aus). Es sieht so aus, also ob nicht “Text prüfen”, sondern “Text erneut prüfen” aufgerufen wurde. Das beschriebene Verhalten entspricht jedenfalls genau dieser Funktion.
Bei mir funktioniert das Markieren auch (LO 6.4.1.2). Was seit neustem nicht mehr funktioniert ist die Funktionstaste F7. Ich gehe davon aus, dass auch das mit LO zusammenhängt. Ich habe an dieser Stelle (zumindest bewusst) nichts verändert.
Da muss ich leider widersprechen. Wenn ich “Text erneut prüfen” anwähle, wird nicht der markierte Bereich z. B. im letzten Kapitel überprüft, sondern das aller erste Kapitel. Wenn ich “Text prüfen” anwähle, wird der Anfang des Kapitels der Markierung bis zum Ende eingescant und analysiert. Es wird nicht der gesamte Text mit einbezogen, was bei “Text erneut prüfen” der Fall ist.
Das Verhalten, dass der gesamte Text eines Kapitels mit gescant wird, hat sich erst nach LT 4,8 verändert. Das liegt nicht an LO, da ich ein Downgrade vollzogen habe. Mit der LT Version 4,8 funktioniert das immer noch. Dort wird nur der markierte Bereich von der “F7”-Analyse erfasst.
@dnaber Wie kann ich aus dem Zip-Paket eine oxt-Datei machen?
Sorry, die Datei ist schon eine OXT-Datei, nur falsch benannt. Einfach das .zip aus dem Dateinamen löschen.
Die Endung .zip wird mir beim Umbenennen nicht anzeigt.
Hier nochmal neu. Noch neuere Version und .oxt als Endung: https://we.tl/t-99PSshrSTl
Zunächst kann ich sagen, dass die neue Version sehr gut funktioniert.
Das erfreut mich sehr. Zudem funktioniert es auch wieder, dass nur der von mir markierte Bereich eingescant wird.
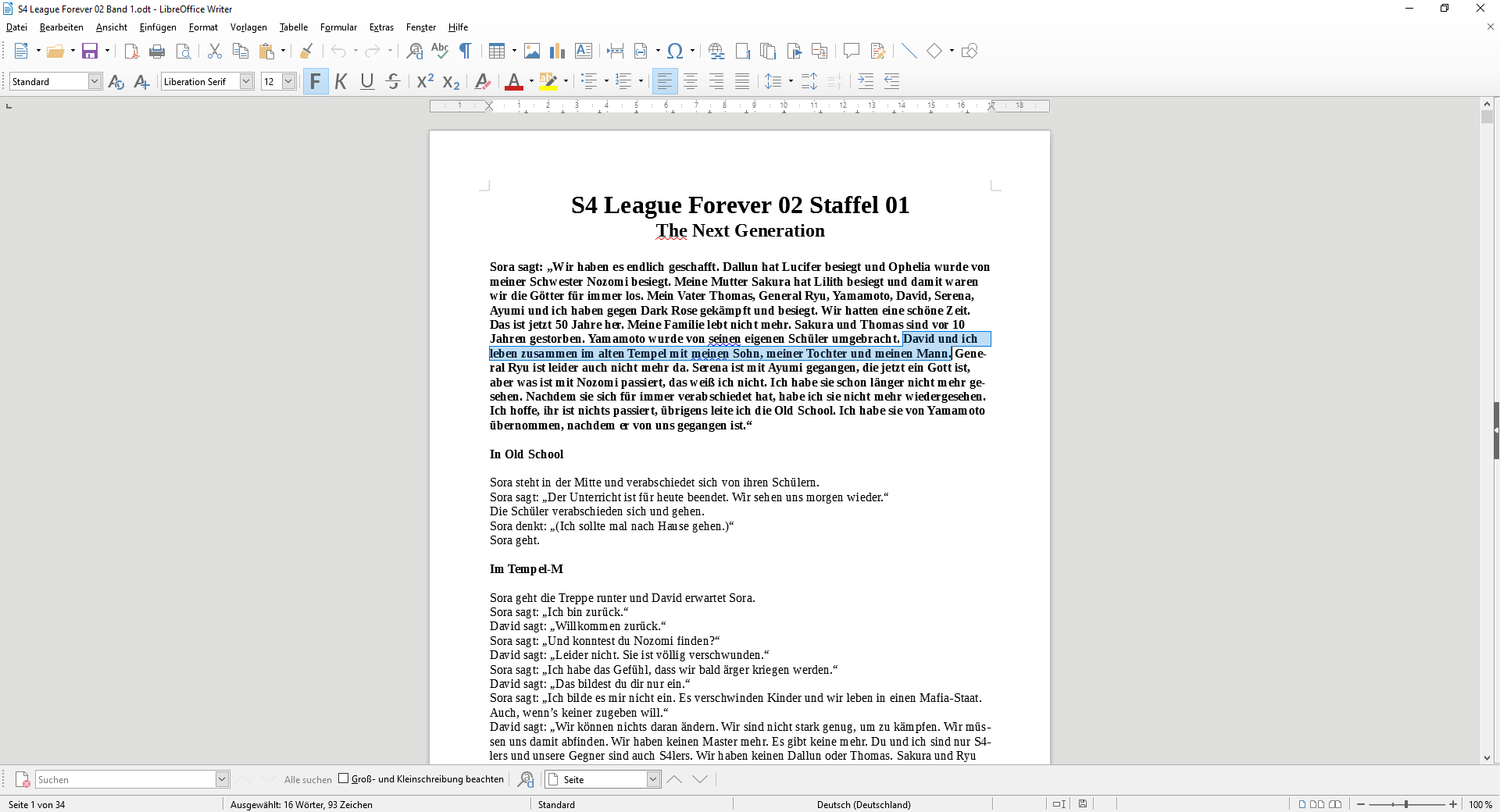
Hier der Beweis:
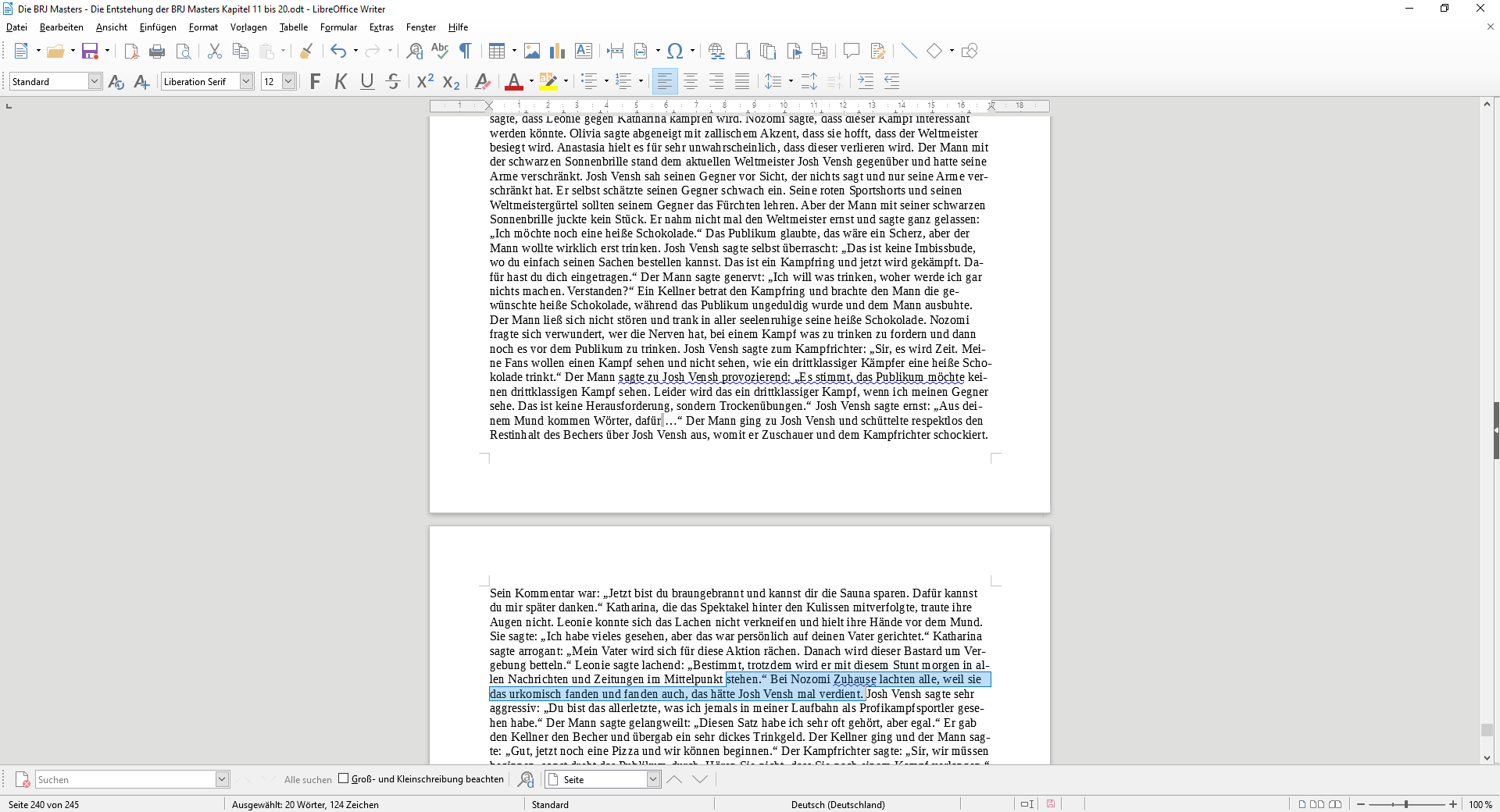
So sah ungefähr meine Markierung aus.
Ihr sieht über meiner Markierung einen Fehlalarm, aber der wurde bei der Analyse nicht beachtet, weil er nicht markiert wurde.
Hier die Aussage von LanguageTool zum Fehlalarm oben.
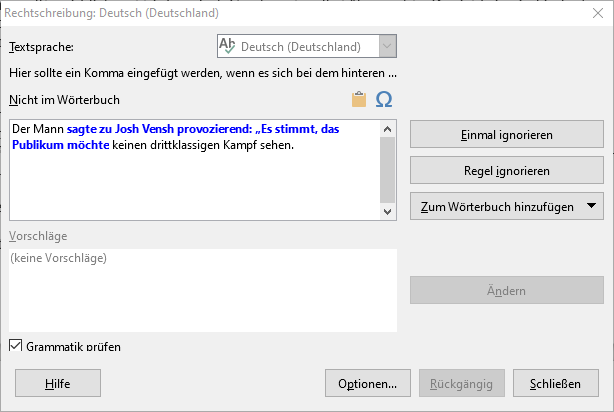
Wir sind uns alle einig, dass hier kein weiteres Komma hingehört.
Das sagt auch die Homepage:
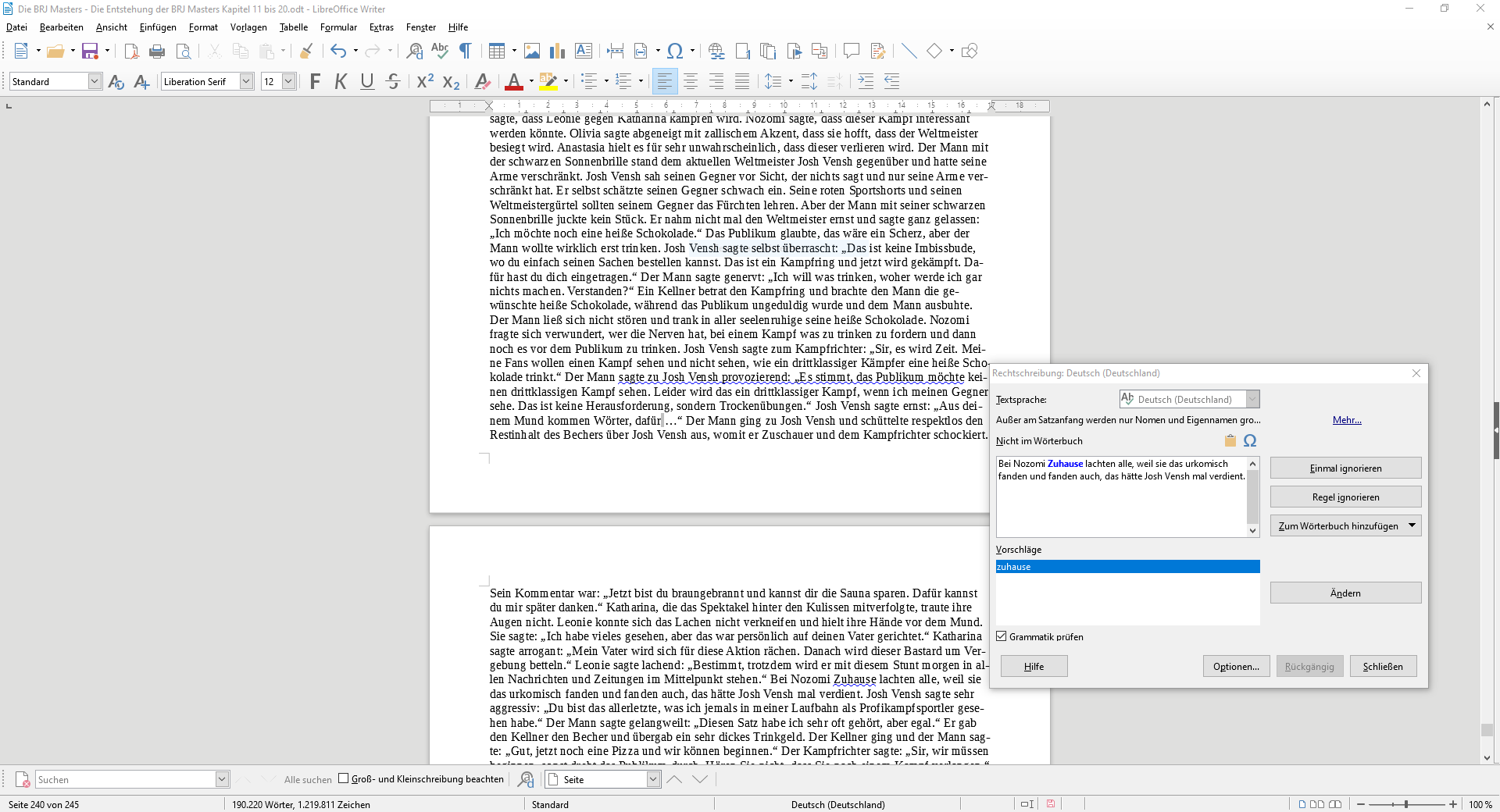
Beim Fehlalarm “Bei Nozomi Zuhause” muss ich das LanguageTool in Schutz nehmen. Dies ist kein Fehlalarm, sondern meine Schuld. Ich habe meine Added.txt nicht erweitert. Sonst würde Nozomi als Vorname erkannt werden und es wird keine Fehlermeldung gezeigt.
Zur Performanz kann ich nur sagen. Sie ist wunderbar. Der Roman mit zehn Kapiteln, der erstmal auch abgeschlossen ist, hat 245 Seiten und 190T Wörter und trotzdem braucht die Analyse nur eine Minute, um Feedback zu geben. Das war auch in der Version 4,8, weswegen dieses Update fabelhaft ist.
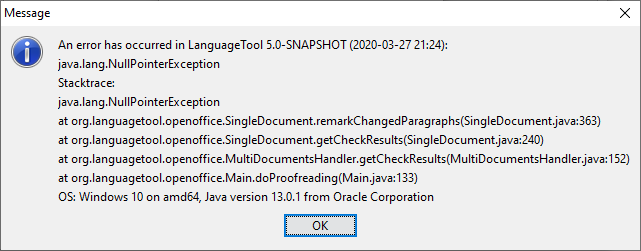
Diese Fehlermeldung kam, weil ich über die Rechtschreibung den Vorschlag angenommen habe.
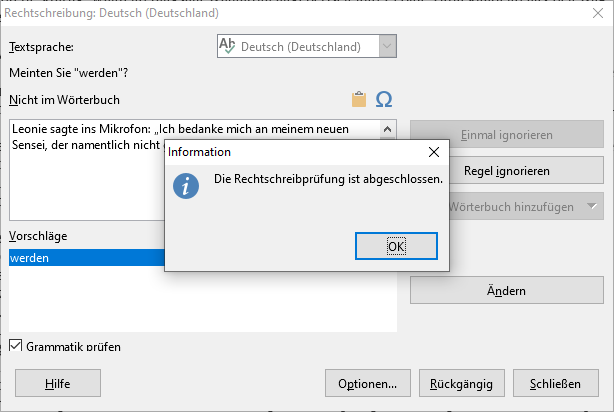
Da diese Version stabiler ist, als die letzten kommt hier ein kleiner härte Test.
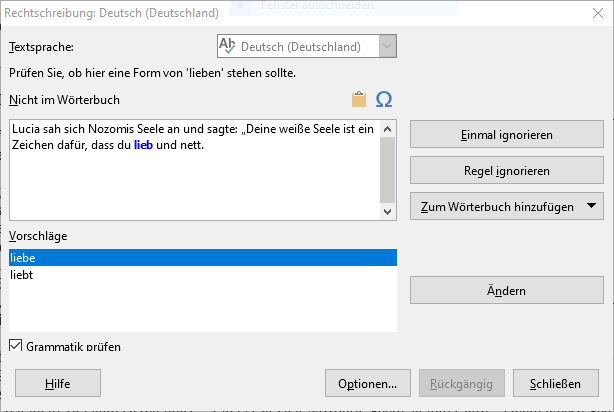
Hinweis Ich weiß, dass hier das Verb “bist” fehlt. Selbst mit der Ergänzung kommt die Fehlalarmfehlermeldung auf der Homepage.
Den kleinen härte Test hat die LT-Version LanguageTool-5.0-SNAPSHOT-20200327-v2 auch bestanden. Das Dokument hatte 448 Seiten und 360T Wörter. Die Analyse zum ersten Fehler hat nur fünf Minuten gedauert. Es wurde alles gescant, ohne Markierung, also alle Kapitel. Das nenne ich mal schnell. Leider ist die Fehlermeldung Fehlalarm, aber das ist egal.
Makiere ich den Fehler “nett und lieb” kommt die Fehler sofort, obwohl das Dokument mitelgroß ist.
Jetzt will ich es aber wissen. Hier kommt mein größtest Dokument. 1,09 Millionen Wörter auf 1300 Seiten.
Gut, das war wohl doch übertrieben. Hier scheint die Grenze vom LanguageTool erreicht worden zu sein.
Die Last des Systems ist nicht gestiegen, aber das Dokument braucht deutlich länger, bis es vollständig geladen und ist zuächst nicht stabil.
Aber jetzt komm das große Aber.
Aus meiner Sicht kann diese Version veröffentlich werden. Ich werde diese heute produktiv nutzen und bin derzeitig sehr zufrieden. Nur die LT-Bug-Fehlermeldungen müssen nur noch verschwieden. Die Fehleralarme bezüglich der wörtlichen Rede, dass das LanguageTool den neuen Satzanfang nicht erkennt, habt ihr behoben. Es kommen nur noch verhäufig Fehleralarme zur Kommasetzung oder zusammengesetzte Wörter. Wenn ihr das nach und nach hinbekommt, habt ihr damit eine sehr stabile und sehr schnelle LT-Version, mit der es sehr viel Spaß macht, zu arbeiten.
Mit freundlichen Grüßen Dallun511